SyFI Team Wins CUDA Kernel Agent Contest at MLSys 2026
At the FlashInfer AI Kernel Generation Contest at MLSys 2026, Team UW SyFI received awards in three categories out of 245 submissions:
- 1st place, GDN Track (Full-Agent Approach)
- 2nd place, GDN Track (Agent-Assisted Approach)
- 3rd place, DSA Track (Full-Agent Approach)
Across all three entries, no humans wrote or edited a single line of kernel source. Every line of Triton, CUDA, and Python we submitted was authored by a coding agent (Claude Code with Claude Opus 4.7, or Codex CLI with GPT 5.5), which we used interchangeably.
We were interested in how far coding agents get on hard performance work, the low-level optimization that usually takes an expert, rather than the boilerplate they already handle. Kernels are a reasonable test: small, hand-tuned code, judged on both correctness and speed against a strong field, on Blackwell hardware (sm_100). The results below are one data point. We describe each kernel and the workflow that produced it, and close with where we think this leads, toward generating a complete serving stack.
The contest
FlashInfer is a library of GPU kernels for LLM inference, and the contest asked teams to generate kernels for a set of serving workloads, evaluated for correctness and speed on NVIDIA Blackwell (sm_100). The two tracks we competed in covered:
- GDN: gated delta-rule (linear-attention) kernels, in both a chunked prefill form and a decode form.
- DSA: DeepSeek-style sparse attention, including a top-k indexer and the sparse attention kernel itself.
Each track ran in two modes that differ in how much the human does. In the full-agent mode, the agent drives the whole loop. In the agent-assisted mode, the human stays in the loop at the level of direction only: the human says what to chase, and the agent does the writing, the diagnosing, and the retuning.
We placed in both modes. The autonomous and the human-steered workflows were each competitive against the field.
The collaboration pattern
The workflow was the same on every kernel:
- Get to correctness in Triton. We asked the agent to write a working Triton implementation against the PyTorch reference first. Triton is the quickest path to something correct and to fast iteration.
- Port to CUDA. Once the Triton version passed, the agent translated it to CUDA.
- Profile and chase. Agents ran Nsight Compute and iterated. The human gave high-level direction, for example “use tensor cores here,” “try warp specialization,” “look at the bank-conflict counter,” or “the min-speedup workload is at small Nt, so make the schedule shape-adaptive.” The agent did the diagnosis, the editing, and the reprofiling, then reported back.
The division of labor was consistent: the human chose what to chase next, the agent chased it, and the human did not open the kernel source. The agent ran the inner loop (read a profiler trace, form a hypothesis, edit, re-measure), which let the human stay at the level of strategy: which bottleneck to attack, when a kernel was correct enough to start optimizing, and where the scoring workload sat. Most of our input was a single sentence pointing at the next thing to look at.
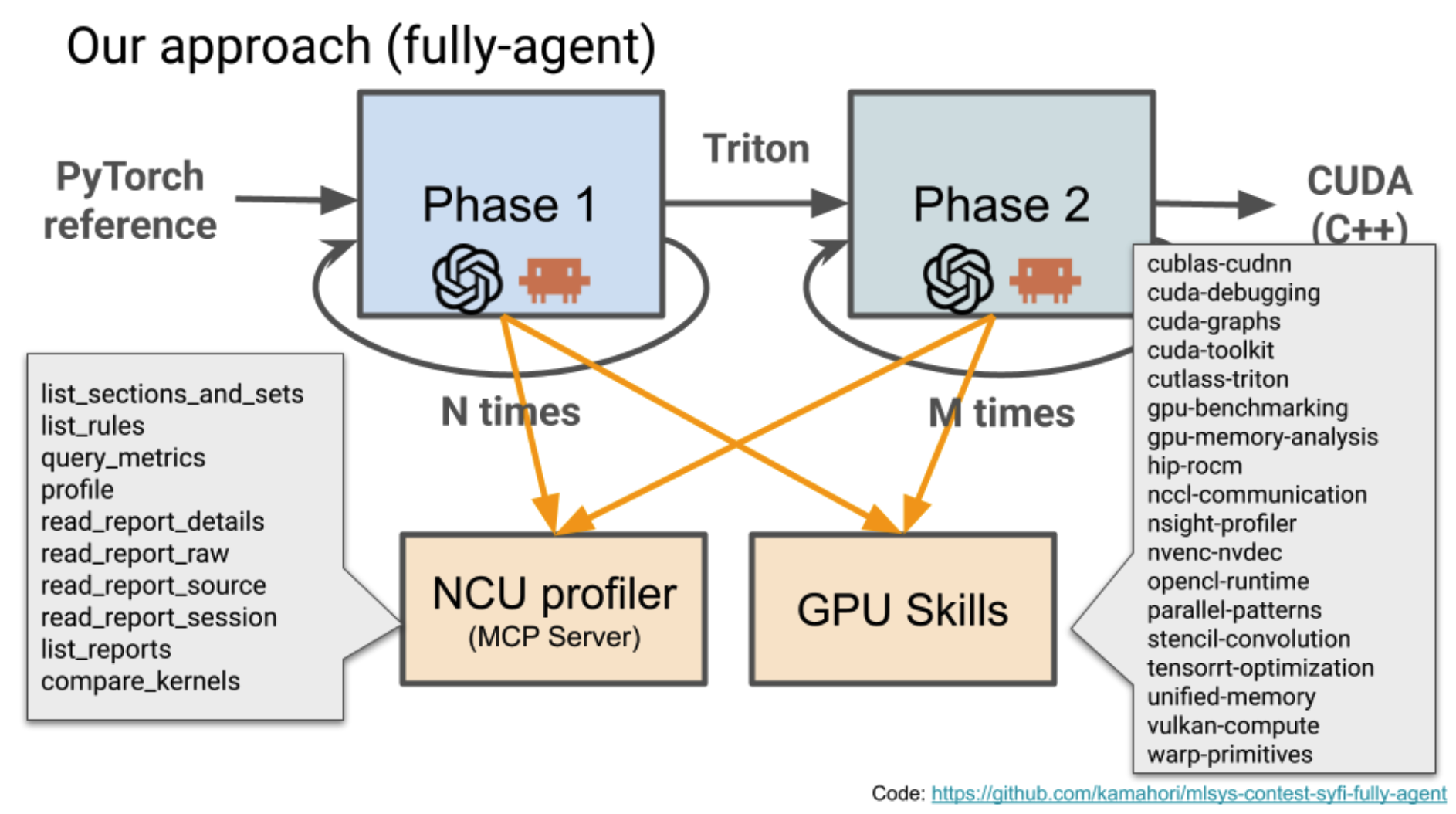
The full-agent entries remove even that division, with the agent setting strategy as well. Both the 1st-place GDN and 3rd-place DSA finishes came from that fully autonomous mode; the agent-assisted GDN entry placed second, behind the hands-off one.
Where this is headed: the whole serving stack
Our recent work, VibeServe, goes one step further than kernels and synthesizes an entire bespoke serving stack. VibeServe is a multi-agent system that builds a complete LLM serving runtime (scheduler, KV-cache management, batching, kernel selection, frontend) specialized to a given model, hardware target, and workload. Across six case studies, it matched vLLM and SGLang on a heavily optimized mainstream setup and reached 1.69×–6.27× speedups on the long-tail deployments generic stacks tend to miss.
The contest is the same approach one layer down. The Triton-to-CUDA-to-Nsight loop we ran by hand has the same shape as VibeServe’s inner loop: an implementer that writes the candidate, a profiler that measures it, and a search policy that picks what to try next. The dead-end search the agent ran on bank conflicts and accumulation order is the kind of thing a stack synthesizer could keep in a skills library so it isn’t repeated. In both cases the work shifts away from writing the specialized system and toward defining what correct and fast mean for a given target.
The contest covered the kernel layer with a human steering; VibeServe covers the whole stack autonomously. The contest results are a small, externally judged check on the same approach.
For more on the stack-level work, the VibeServe blog post and paper have the full design and per-iteration logs, and the code is at github.com/uw-syfi/vibe-serve.
Team UW SyFI: Keisuke Kamahori, Steven Gao, Vic Shihang Li, Wei Shen, and Yile Gu.
The agent-assisted submission and all five kernels are open-source: github.com/kamahori/mlsys-contest-syfi-agent-assisted and github.com/kamahori/mlsys-contest-syfi-fully-agent