Let AI Agents Write Your Serving Stack with VibeServe
Keisuke Kamahori, Shihang Vic Li, Simon Peter, Baris Kasikci
May 12, 2026
TL;DR: Generic LLM serving stacks cover the mainstream use cases well, but struggle on the long tail of new models, accelerators, and workloads. VibeServe is a multi-agent system that synthesizes a complete serving runtime end-to-end, specialized to a user-specified model, hardware, and workload. Across six case studies, it matches vLLM and SGLang on a heavily optimized mainstream setup (Llama-3.1-8B on H100) and delivers 1.69×–6.27× speedups on non-standard ones. This is early evidence that AI agents can build an entire system end-to-end and beat human-engineered baselines on long-horizon performance work.
- 📄 preprint: https://arxiv.org/abs/2605.06068
- 💻 code: https://github.com/uw-syfi/vibe-serve
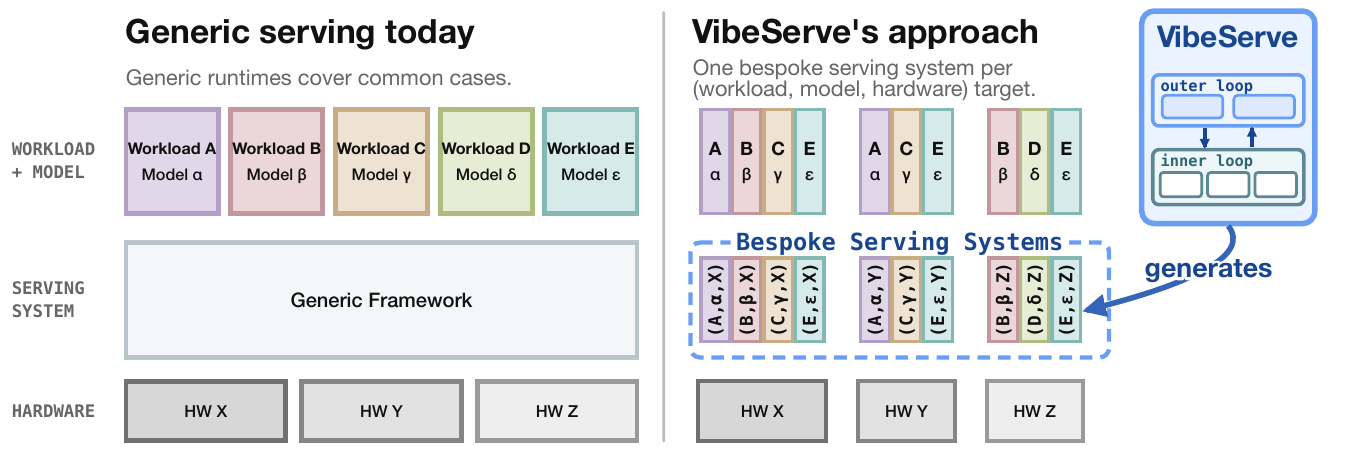
Figure 1. One generic runtime for every workload, model, and hardware (left) vs. one bespoke runtime per target, generated by an agentic loop (right).
The tension between generic and specialized systems is a recurring one in systems research. Generic runtimes amortize engineering effort but pay a portability tax, since abstractions that fit every target rarely fit any target perfectly. Operating systems work has traditionally tried to push toward specialization (e.g., the Synthesis kernel, exokernels, and unikernels), but per-target engineering cost has kept specialization out of the mainstream.
LLM serving sits at the same crossroads today, with an even sharper long tail along three axes that generic runtimes routinely miss. Diverse model architectures require specialized stacks for multimodal models. Some workload patterns allow specialized optimizations that generic systems may struggle with. There is also a wide range of hardware, each requiring different optimization strategies. Closing this gap means moving specialization from build time to generation time, i.e., generating a serving runtime per deployment rather than retrofitting a general-purpose one. We call this approach VibeServe (Figure 1).
Why end-to-end synthesis is hard
Coding agents change the cost calculus that historically kept per-target specialization unattractive. Agentic loops have been shown effective on isolated components such as GPU kernels, individual algorithms, systems policies, and fault diagnosis.
Scaling those agentic loops up to an end-to-end serving runtime is much harder. The implementation spans multiple layers, including request scheduling, KV-cache management, batching, kernel selection, and the frontend, well beyond any single agent’s context window. VibeServe is our attempt to build an agentic loop that produces serving systems that are correct, competitive on mainstream deployments, and substantially faster on long-tail ones.
VibeServe approach: two loops, fresh contexts, persistent state
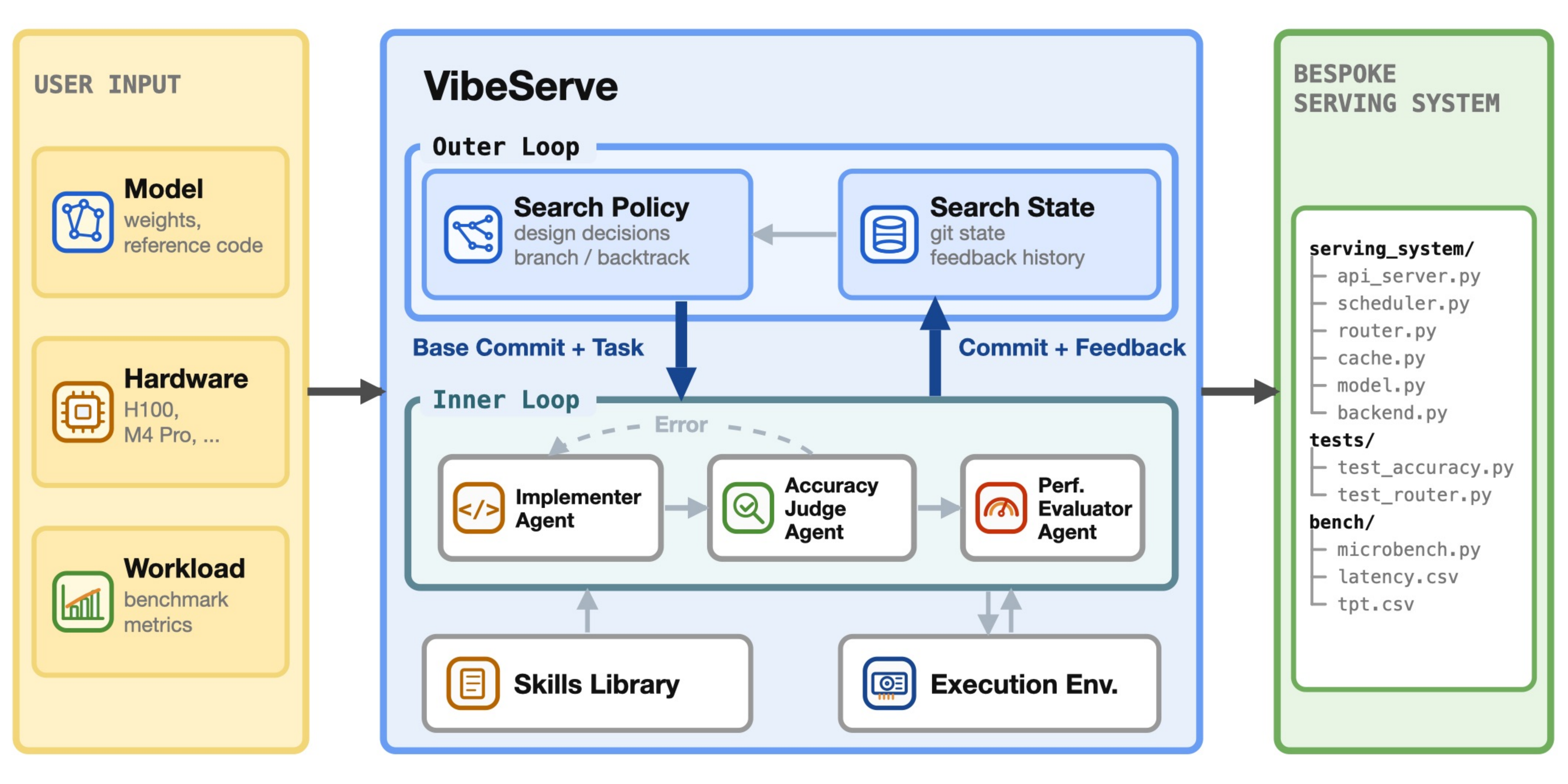
Figure 2. VibeServe architecture: an outer planning loop dispatches rounds to an inner loop where Implementer, Accuracy Judge, and Performance Evaluator agents collaborate on a shared workspace backed by a skills library and an execution environment.
At a high level (Figure 2), VibeServe takes three user-provided artifacts (model, hardware target, and workload) and synthesizes a bespoke serving system. The framework operates on two nested optimization loops, with persistent state kept outside any agent’s context window to avoid compaction drift.
- Outer loop: a search policy over validated checkpoints. Maintains an issue backlog, a long-term memory file, and a git history of validated checkpoints, using them to pick the next optimization direction and dispatch a concrete task to the inner loop. The memory file lets the orchestrator distinguish “this implementation needs debugging” from “this direction is unsuitable,” a separation that prevents the loop from either chasing failed attempts or discarding promising directions after one buggy try.
- Inner loop: three specialized agents on a shared workspace. An Implementer writes the candidate system, an Accuracy Judge validates correctness and inspects the diff for reward-hacking patterns, and a Performance Evaluator profiles validated implementations. Keeping these roles in independent contexts is deliberate. A combined agent can quietly weaken its correctness criteria to land a hard optimization, but a fresh-context Judge cannot.
- Skills library: extensibility through skills, not framework edits. A dedicated Agent Skills library distilled from existing serving engines and the literature, covering techniques like continuous batching, paged-KV caching, and FlashAttention variants. New models, accelerators, and optimizations enter as new skill entries rather than core framework changes.
See the 📄 paper and 💻 code for the full design.
Does it work?
We evaluated VibeServe across six deployment targets spanning workload pattern, model architecture, and hardware. The Implementer, Judge, and Evaluator were each instantiated with Codex CLI.
Case Study A: Standard LLM serving (Llama-3.1-8B on H100)
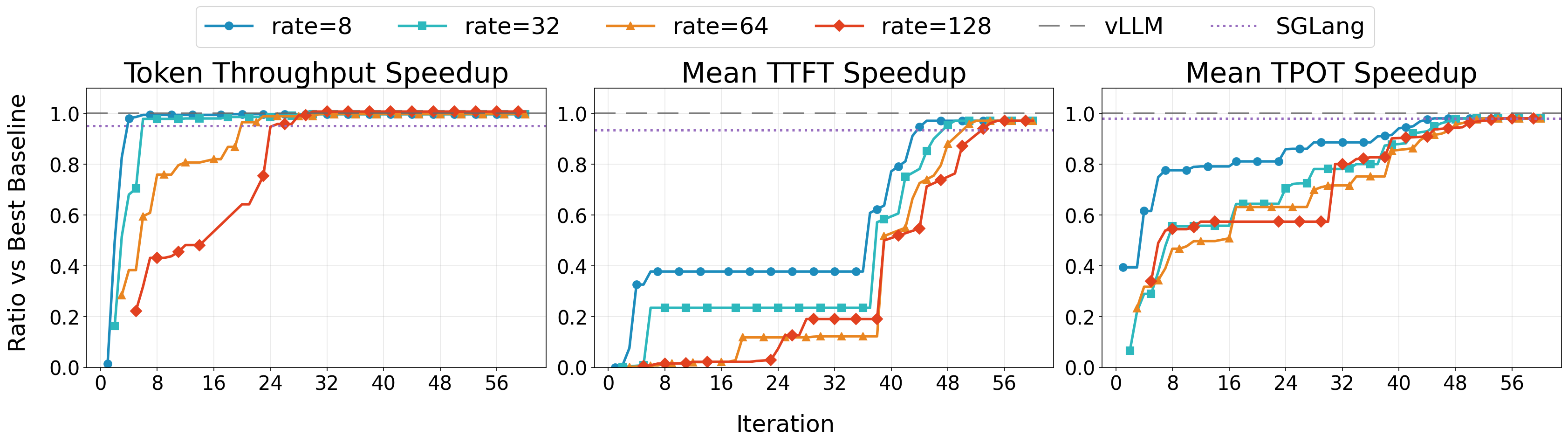 Figure 3. Throughput, TTFT, and TPOT relative to vLLM over 60 iterations. Each line is one of four request rates (8, 32, 64, 128 req/s). 1.0 = parity with vLLM, higher is better.
Figure 3. Throughput, TTFT, and TPOT relative to vLLM over 60 iterations. Each line is one of four request rates (8, 32, 64, 128 req/s). 1.0 = parity with vLLM, higher is better.
A natural first question when considering per-deployment specialization is whether it incurs a performance penalty. To test this, we ran VibeServe on Llama-3.1-8B-Instruct with an NVIDIA H100, a highly optimized mainstream setup. Across 60 iterations, VibeServe’s generated runtime matched vLLM and SGLang on token throughput, time-to-first-token (TTFT), and time-per-output-token (TPOT) (Figure 3). The agent prioritized throughput, achieving parity with vLLM around iteration 30, then shifted focus to reducing latency, further improving TTFT and TPOT throughout iterations 30–60.
Case Study B-F: Non-standard scenarios
We then probed the long tail along the three axes that historically drive serving-system effort (model architecture, workload pattern, and hardware). Each of the five non-standard case studies stresses at least one of these axes (tagged with #model, #workload, #hardware below). They are niche relative to mainstream chatbot serving, but each is a realistic deployment that someone is actually running today, and together they cover the dimensions on which generic stacks tend to break down. The per-case sections below expand each one, with the per-iteration trajectory inline. Dashed line at 1.0 is parity with the baseline; higher is better, except for Case F (H100), where the y-axis is p50 latency in ms (lower is better).
Case Study B: Code editing with predicted outputs (Qwen3-32B on H100) — 5.95× vs vLLM
#workload
Some applications can tell the serving system, at request time, roughly what the answer will look like. A serving system that exposes a predicted-output interface can turn that hint into a large latency win. Code editing is the canonical example. When a user asks the model to fix a bug or rename a symbol, the edited file is usually the original file with small, localized changes. The pre-edit file is therefore a near-perfect prediction of the output, and OpenAI’s predicted-outputs API exposes this interface, allowing the client to pass predicted text alongside the prompt. Under the hood, this is a special form of speculative decoding in which the draft is free, with no draft model and only user-supplied tokens. The engine can run a window of K predicted tokens through the target model in a single forward pass, accept the longest matching prefix, and fall back to one-token autoregressive decoding at the first mismatch. When overlap is high, latency can drop by nearly a factor of K with no extra model compute.
Generic serving stacks support draft-model speculative decoding, but they do not expose predicted outputs as a first-class interface. Adding that support is not just an API change. It cuts across the scheduler, sequence-group state, and sampler. The engine needs a per-request predicted-token stream, a verifier loop that advances through that stream until divergence, and precise fallback semantics after a mismatch. A bespoke runtime can instead make predicted outputs part of the request lifecycle from the beginning.
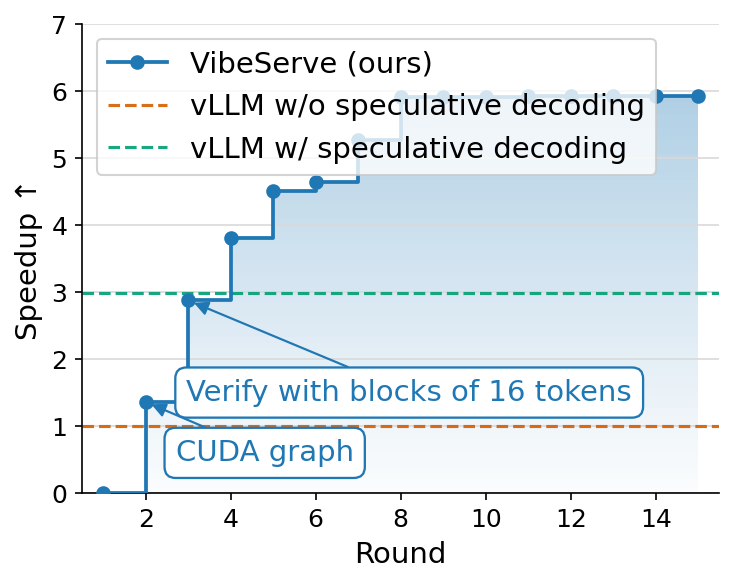
We tried VibeServe at Qwen3-32B on H100 with that interface and the CodeEditorBench workload. Iteration 2 added CUDA-graph capture (1.35×). By iteration 3, it had a working predicted-output verifier that proposed tokens from the user-supplied prediction in 16-token blocks and verified them in a single target-model forward pass, reaching 2.9×, already on par with vLLM’s draft-model speculative decoder at zero draft-model compute. By iteration 14, with tuned block sizing and acceptance bookkeeping, the generated system reached 5.95× over vanilla vLLM and roughly 2× over vLLM with draft-model speculative decoding.
Case Study C: Hybrid-architecture prompt caching (Olmo-Hybrid-7B on L4) — 3.45× vs vLLM
#model #workload
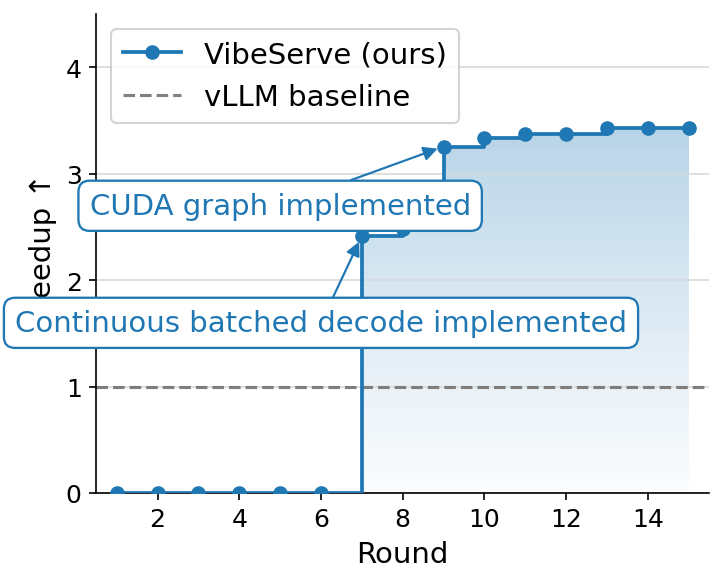
A growing number of recent models interleave self-attention layers with state-space-model (SSM) or linear-attention layers for smaller KV cache capacity. A pure attention model carries a KV cache that grows linearly in sequence length, which becomes the dominant cost in long-context serving, while SSM/linear-attention layers compress the entire past into a fixed-size tensor. Replacing some attention layers with SSM layers can cut KV-cache capacity dramatically while preserving quality. But the same property that saves memory complicates prefix caching. In a pure-attention model, caching a shared prefix means caching that prefix’s KV entries token-by-token, and multiple requests can read from the same per-token cache. SSM state, by contrast, is not per-token. Each layer holds a single recurrent state that summarizes the entire history up to the current step, updated in place. To reuse a long shared prefix across requests, a serving system therefore has to snapshot the SSM state at the prefix boundary for every request, in addition to the per-token attention KV blocks. On a GPU with limited memory facing long contexts, those per-request SSM snapshots can themselves be large enough to crowd out other tenants, and getting the cache invariants wrong silently corrupts outputs. Knowing the workload at system design time changes the picture. If the system is told up front that requests share a long common prefix (as in RAG or system-prompt-heavy serving), it can snapshot the SSM state once at that prefix boundary and amortize it across all requests, instead of paying the per-request snapshot cost a workload-agnostic runtime must assume in the worst case.
Olmo-Hybrid-7B (Gated DeltaNet + attention) is a representative target. We ran a RAG-style workload on an NVIDIA L4 where requests share a 32k-token prefix, append a 128-token unique suffix, and generate 128 output tokens. Iterations 1–6 failed accuracy gates while VibeServe wired up the dual cache (attention KV blocks plus per-DeltaNet recurrent-state snapshots taken at the prefix boundary). Iteration 7 landed continuous batched decode against the shared state (2.45×). Iteration 9 added CUDA-graph capture (3.25×). The system plateaued near 3.45× over vLLM, which has to recompute the 32k prefix per request because it cannot share DeltaNet state across requests.
Case Study D: Streaming ASR (Moonshine on L4) — 1.69× vs vLLM plugin
#model #workload
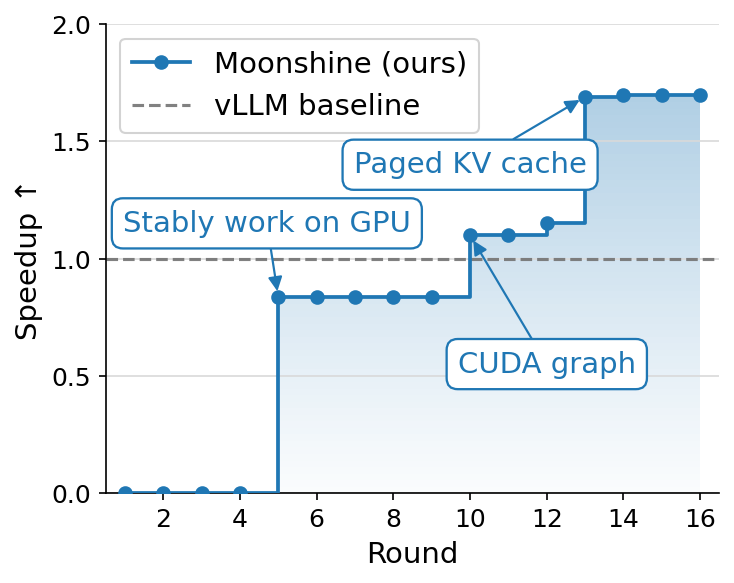
Streaming automatic speech recognition wants to start emitting transcript tokens before the user finishes talking. The classic ASR encoder–decoder design, most notably OpenAI’s Whisper, works against that goal. The speech encoder runs full self-attention over the entire audio segment, so every time a new audio chunk arrives, the engine has to re-encode the whole utterance from scratch. End-to-end latency grows with the length of the user’s turn. New models like Moonshine Streaming change the encoder side of this picture. Its speech encoder uses sliding-window attention, where each acoustic frame attends only to a bounded local window of previous frames. The architecture is designed so that, in principle, a serving system can keep a per-stream cache of the encoder’s hidden state, append the new audio chunk, and only run the encoder over the new frames (plus the relevant window) rather than re-encoding from scratch. However, the latency win is unlocked only when the serving system actually does that incremental encoding and caches the per-stream encoder state across chunks.
That is exactly where mainstream stacks fall short. vLLM supports plugging in new model architectures, and Moonshine can be implemented as a vLLM model plugin, but the encoder path in vLLM is built around one-shot encoding for models like Whisper, with no first-class notion of per-stream encoder cache management. Adding that means touching the scheduler, the request lifecycle, and how encoder state interacts with the KV cache, well beyond what a plugin is allowed to do. A bespoke serving system can instead treat per-stream encoder caches as a first-class object and lay out its scheduler around them.
We measured TTFT at concurrency 32 on an L4 GPU, with clients sending audio chunks every 2 seconds, against a vLLM-Moonshine plugin baseline. Iteration 5 reached a working but sub-baseline configuration (0.84×) by aligning the per-stream encoder cache with Moonshine’s sliding-window attention. Iteration 10 added CUDA-graph capture (1.1×). Iteration 13 added a paged KV cache for per-stream encoder state, reaching 1.69× and holding through iteration 16. The win comes from making per-stream encoder cache management first-class, which the plugin path simply does not expose.
Case Study E: Local constrained JSON decoding (Llama-3.1-8B on a MacBook) — 2.6× vs autoregressive
#workload #hardware
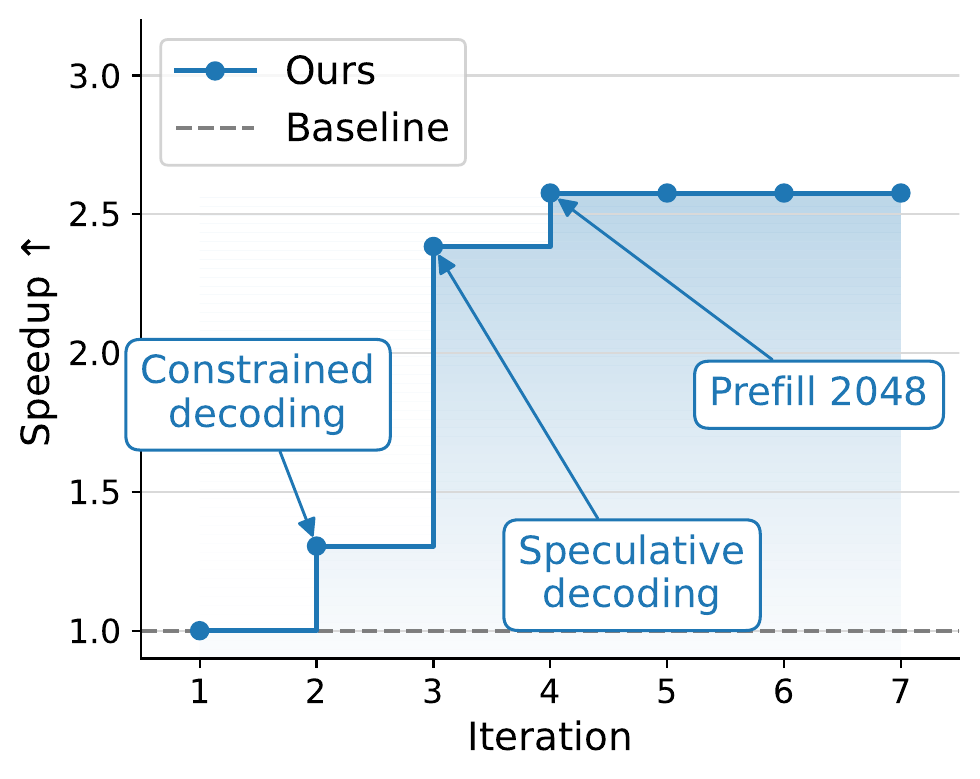
When an application asks the model to emit JSON conforming to a schema, a lot of the output is grammatically forced. Every object key the schema declares, the surrounding "..." and : and , separators, and the leading characters of typed values (true / false, the opening digit of a number, the opening quote of a string) are uniquely determined by where the decoder is in the grammar. A constrained decoder that knows the schema can recognize these runs and do jump-forward decoding without invoking the LLM for those positions at all. Engines like XGrammar and Outlines build the schema into a pushdown automaton and pre-compute a per-state token mask so that, when the grammar admits exactly one continuation, multiple tokens can be appended in a single step at near-zero compute.
We also wanted to see whether VibeServe’s approach generalizes off NVIDIA, so we ran this case study on a MacBook (Apple M3 Pro, 36 GB) on JSONSchemaBench, targeting Llama-3.1-8B-Instruct. The hardware switch matters. Apple Silicon’s unified-memory model and the MLX runtime have very different bandwidth and kernel-dispatch characteristics from CUDA, so optimizations that pay off on H100 may be no-ops or regressions here, and tooling like CUDA Graphs is unavailable. From a 22.1 s vanilla autoregressive baseline, VibeServe first added XGrammar-based constrained decoding (16.9 s), then layered speculative decoding with a Llama-3.2-1B-Instruct-4bit draft against the 8B-8bit target at K=4, reaching 9.3 s. A 3B-4bit draft was actually slower because the 1B’s lower per-step cost outweighed its lower acceptance rate. Bumping mlx_lm’s prefill_step_size from 512 to 2048 prefilled the ~1300-token prompts in one chunk, yielding 8.6 s (2.6×). K/V quantization, alternative K, and mx.compile were tried and did not help, useful to know and exactly the kind of dead-end search that the loop runs so a human does not have to.
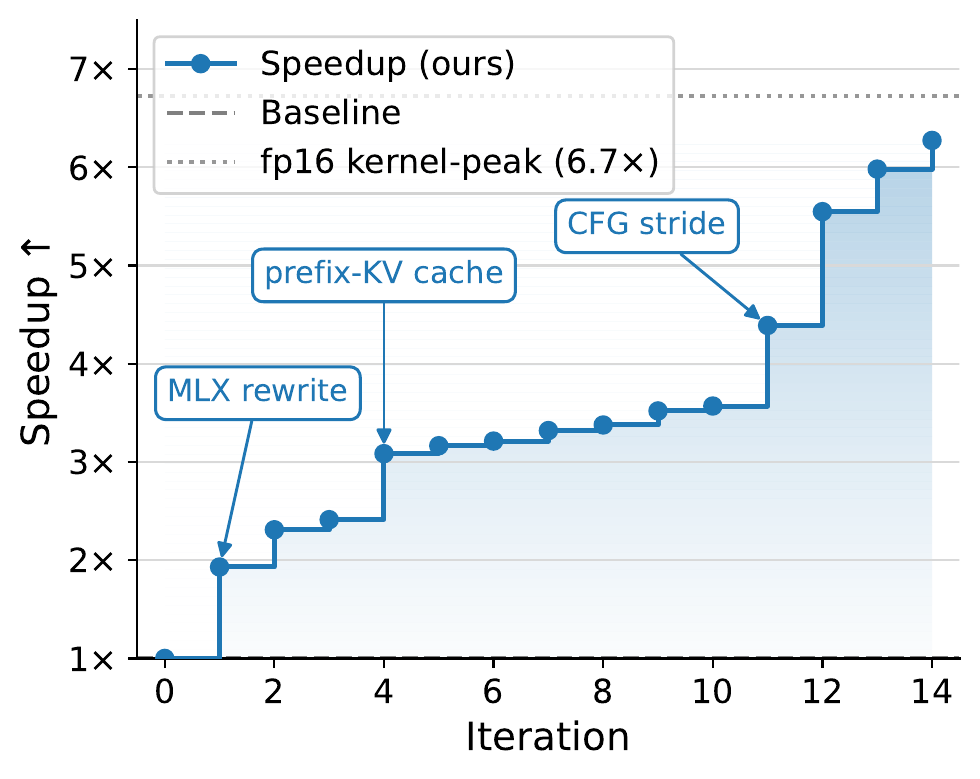
Case Study F: Local image generation with Show-o2 (MacBook and H100) — 6.27× on MBP, 21.4% lower p50 on H100
#model #hardware
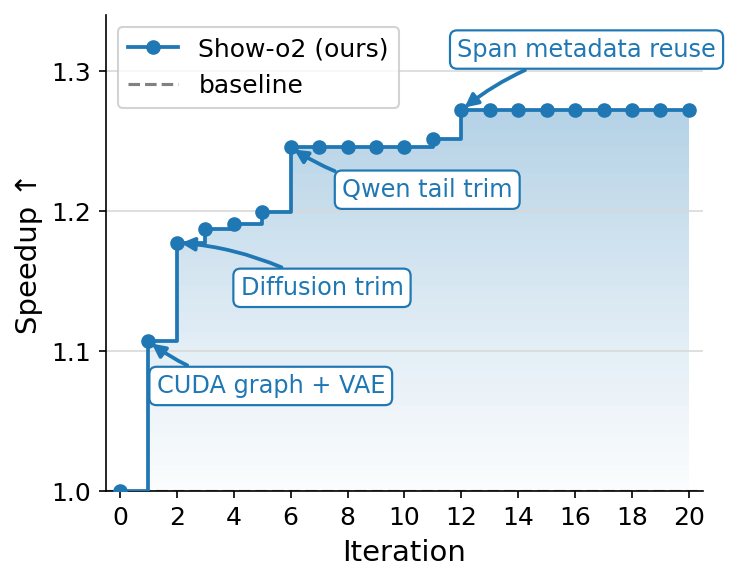
Show-o2 is a native unified multimodal model, where a single backbone handles both text and image generation, rather than bolting an image decoder onto a language model. Concretely, it builds on a 3D causal VAE that turns images (and video frames) into continuous latents, fuses them with text token embeddings into one sequence, and feeds that sequence through a Qwen2.5-derived Transformer body. The body then drives two output heads in the same forward pass. A language head produces text tokens autoregressively, and a flow-matching head denoises the image latents through K diffusion-like steps. Text generation, image generation, and text-conditioned image generation all reuse the same backbone with different head schedules.
That hybrid structure is precisely what mainstream serving stacks have no place to put. vLLM is built around the autoregressive decode loop, and vLLM-Omni adds disaggregated stages for omni-modal models, but neither supports models that interleave an autoregressive language head and a multi-step flow-matching head over a shared Transformer body in one request. There is no first-class abstraction for “run the body once, then iterate the diffusion head K times against the cached body state, then sometimes re-enter the body,” so neither system can run Show-o2. There is no obvious off-the-shelf baseline and the experiments below compare against the model’s reference PyTorch implementation. We ran two targets:
- H100 (left). We target the Show-o2 1.5B-HQ checkpoint at 432×432 text-to-image. Over 20 iterations, p50 latency fell from 873 ms to 687 ms (21.4%). Gains were front-loaded. Iteration 1 contributed 9.7% (CUDA-graph replay/prewarm, VAE/postprocess layout). Iteration 2 added 5.4% (trim inactive diffusion tokens, restrict AdaLN to the active image span). Iteration 6 trimmed the Qwen tail (3.1%). Later passes mostly mapped the limits. Aggressive trimming and naive batching regressed quality, FlashAttention-2/GQA/
torch.compile/fp16 altered outputs or produced NaNs, and Qwen prefix reuse yielded no gain because the text prefix is tiny next to the 730-token image span. - MacBook (right). VibeServe first ported the Qwen2.5-1.5B body and 10-block diffusion head to MLX and elided a redundant SigLIP pass on noisy latents (2.4×). Cross-step redundancy then dominated. Prefix-KV caches on the body and head, plus a prefill trim, brought warm latency to 3.5× with the body at ~92% of fp16 compute peak. Quantization regressed on the compute-bound body, and only int4 on the bandwidth-bound head survived. A classifier-free-guidance stride at K=16 (skipping the unconditional branch on K−1 of every K steps and reusing the cached
v_uncond) reached 15.54 s, a 6.27× speedup over PyTorch-MPS and within ~7% of a 14.5 s physics floor computed from kernel-perfect per-step times.
Takeaways and what comes next
Across all six case studies, VibeServe matched mainstream baselines where they were strong and delivered 1.69×–6.27× speedups where they were weak or absent. More broadly, the implication extends beyond LLM serving. The same tension between generic abstraction and target-specific performance shows up across operating systems, databases, compilers, and distributed runtimes. VibeServe shows that agent-directed end-to-end system design is possible, and the bottleneck has shifted from writing specialized systems toward defining system correctness and performance goals. The recipe is a target-agnostic harness plus a skills library, with the agentic loop assembling a bespoke system per deployment instead of one general-purpose runtime absorbing every special case.
If you want to try VibeServe or contribute skills for new architectures, accelerators, or workloads, the code is at https://github.com/uw-syfi/vibe-serve and the paper has the full design and per-iteration logs.
We are grateful to our collaborators at the University of Washington for the discussions and feedback that shaped this work, and to Modal for providing the compute credits.