Quest: Query-Aware Sparsity for Efficient Long-Context LLM Inference
Jiaming Tang, Yilong Zhao, Kan Zhu, Guangxuan Xiao, Baris Kasikci, Song Han — International Conference on Machine Learning (ICML) (2024)
LLM Serving
Keywords: Large Language Models Long-Context Inference Attention Optimization KV Cache Management Sparse Attention
Overview
As LLMs scale to handle increasingly longer contexts (128K-1M tokens), self-attention computation becomes a major bottleneck. Quest introduces a breakthrough approach: query-aware sparsity that dynamically identifies and loads only the most critical KV cache pages needed for each attention operation, dramatically reducing computation and memory transfer overhead.
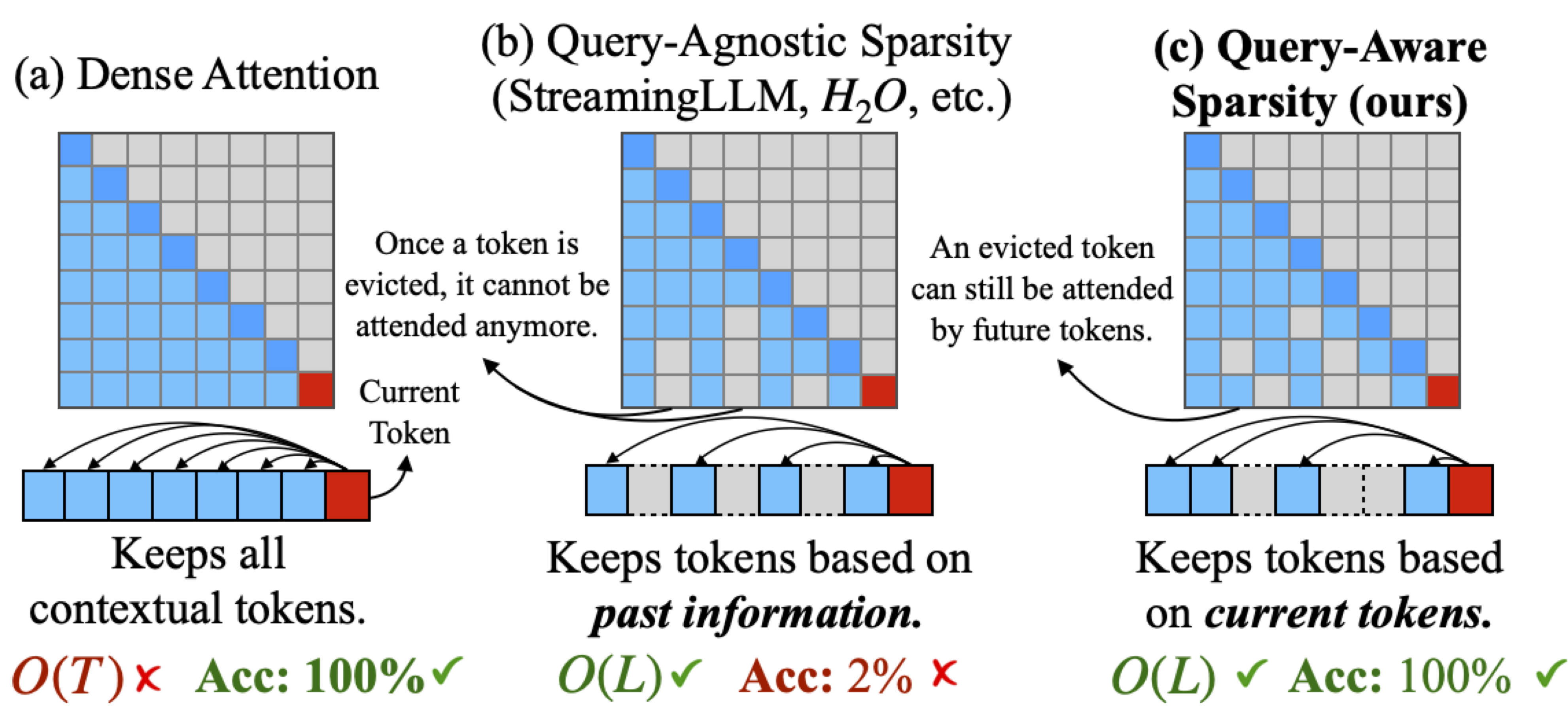
Unlike previous static sparsity methods that pre-determine important tokens, Quest makes query-dependent decisions at runtime, ensuring that criticality is determined based on the actual query context—leading to both efficiency gains and accuracy preservation.

The Long-Context Challenge
Long-context LLMs face severe performance bottlenecks:
- Massive KV Cache: A 128K token context requires gigabytes of KV cache storage
- Memory Bandwidth Wall: Transferring entire KV cache from HBM to compute units dominates latency
- Quadratic Attention Cost: Self-attention scales O(n²) with sequence length
- Throughput Collapse: Longer contexts mean fewer concurrent requests can be served
Traditional solutions either sacrifice accuracy (aggressive pruning) or fail to address the fundamental memory bandwidth bottleneck.
Core Innovation
🎯 Query-Aware Criticality Estimation
Quest’s key insight: token criticality depends on the query. A token critical for one query may be irrelevant for another.
How it works:
- Min-Max Tracking: Maintains minimal and maximal Key values for each KV cache page
- Query-Based Estimation: Uses incoming Query vectors to estimate attention scores
- Top-K Selection: Loads only the K most critical pages for computation
- Dynamic Adaptation: Criticality changes with each query, enabling fine-grained selectivity
This approach contrasts with static methods that:
- ❌ Pre-select important positions (fails for diverse queries)
- ❌ Use fixed attention patterns (ignores content-dependent importance)
- ❌ Apply uniform sparsity (wastes computation on irrelevant tokens)
⚡ Efficient Page-Level Management
Quest operates at the page granularity rather than individual tokens:
- Coarse-grained operations: Reduces metadata overhead
- Memory-aligned: Pages map naturally to hardware memory hierarchy
- Prefetch-friendly: Enables efficient batch loading of critical pages
- Cache-conscious: Optimizes for modern GPU memory systems
🚀 Optimized CUDA Kernels
Custom kernel implementations for sparse attention:
- Fused page selection: Combines criticality computation with attention
- Dynamic loading: Fetches only selected pages from HBM
- Efficient indexing: Minimizes pointer chasing and indirection overhead
- Tensor core utilization: Maintains high compute throughput despite sparsity
Performance Benchmarks

Self-Attention Speedup
- Up to 7.03x faster compared to dense attention
- Speedup increases with longer contexts (more opportunity for sparsity)
- Consistent gains across different model sizes
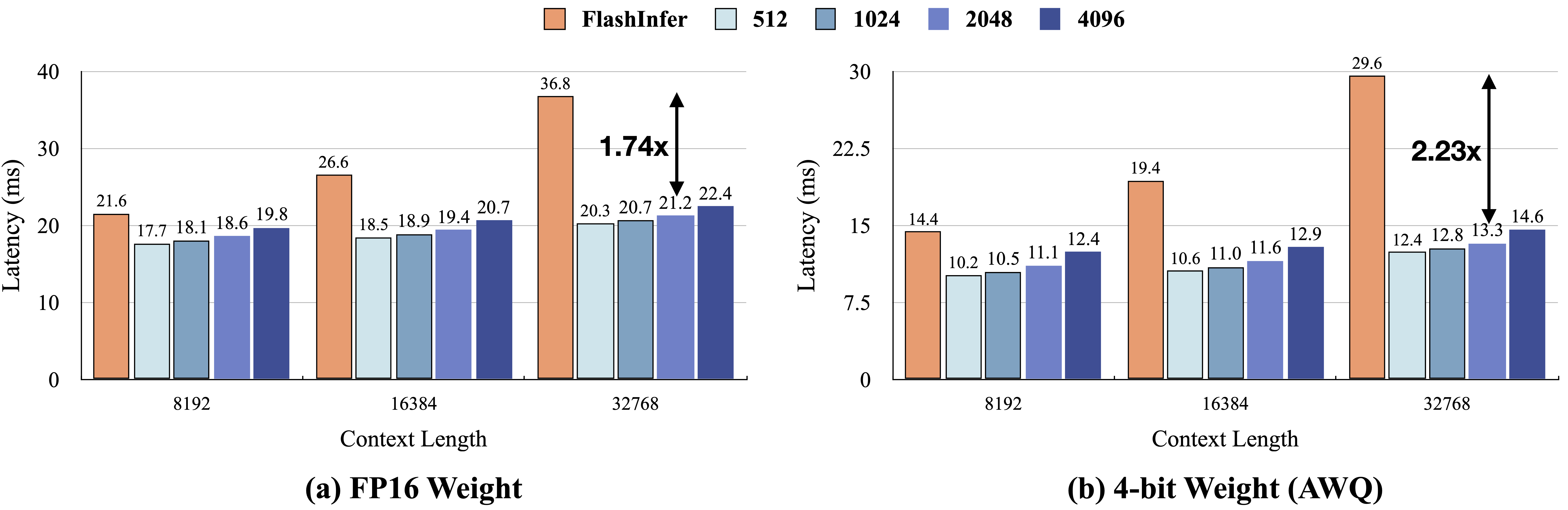
End-to-End Latency Reduction
- 2.23x faster inference on long-context tasks
- Maintains speedup in real-world workloads
- Scales efficiently from 128K to 1M token contexts
Accuracy Preservation

- Negligible accuracy loss on long-dependency tasks
- Maintains quality on:
- Document question-answering
- Long-form summarization
- Multi-turn dialogue with long history
- Code understanding with large contexts
Technical Approach
Quest’s pipeline consists of:
- Initialization: Organize KV cache into fixed-size pages with min-max metadata
- Query Processing: For each attention operation, compute Query vectors
- Criticality Estimation: Score each page using Query-Key min-max bounds
- Top-K Selection: Identify and load the K most critical pages
- Sparse Attention: Compute attention using only loaded pages
- Result Composition: Combine partial results into final attention output
This design ensures that only relevant context is loaded and computed, dramatically reducing both memory traffic and computational overhead.
Key Takeaways
Dynamic query-aware sparsity is the key for improving accuracy. Unlike static sparsity patterns that apply the same pruning regardless of input, Quest’s query-aware approach dynamically determines which KV cache pages are critical based on the actual query. This dynamic selection preserves accuracy because different queries naturally attend to different parts of the context, and Quest adapts to these query-specific attention patterns.
KV cache eviction vs. selection represent different trade-offs. KV cache eviction policies (like removing old tokens) reduce memory usage and increase batch size by physically discarding cache entries, but require careful strategies to avoid accuracy loss. In contrast, KV cache selection policies (like Quest) keep all cache in memory but selectively load only relevant pages during attention—this improves performance through reduced memory bandwidth while maintaining full accuracy, though without reducing memory capacity. Quest chooses the selection approach to prioritize accuracy and bandwidth optimization over memory footprint reduction.