Piper: Towards Flexible Pipeline Parallelism for PyTorch
Megan Frisella, Arvin Oentoro, Xiangyu Gao, Gilbert Bernstein, Stephanie Wang — Practical Adoption Challenges of ML for Systems (PACMI) (2025)
Distributed Training
Keywords: ML Compilers Distributed Training Pipeline Parallelism
Overview
Pipeline parallelism is a key distribution technique for training large models, however it is not frequently adopted due to its implementation complexity. Existing state-of-the-art frameworks have adopted pipeline parallelism but fail to achieve generality in the models and execution schedules they support. Piper is a PyTorch pipeline parallelism package that seeks to give the user full control over the execution schedule without the burden and error-proneness of low-level coordination. Piper achieves competetive preliminary performance with state-of-the-art frameworks pipelining Llama and CLIP models.
Pipeline-Parallel Schedules
Pipeline-parallel execution schedules describe where and when forward and backward stages execute. They overlap multiple batches of data to improve utilization. Different schedules make different tradeoffs between throughput, memory, and communication. For example, interleaved 1F1B partitions the model into twice as many stages compared to 1F1B and interleaves execution between devices to enable overlapping multiple forward-backward streams. This decreases idle time at the cost of additional peer-to-peer communication at stage boundaries.
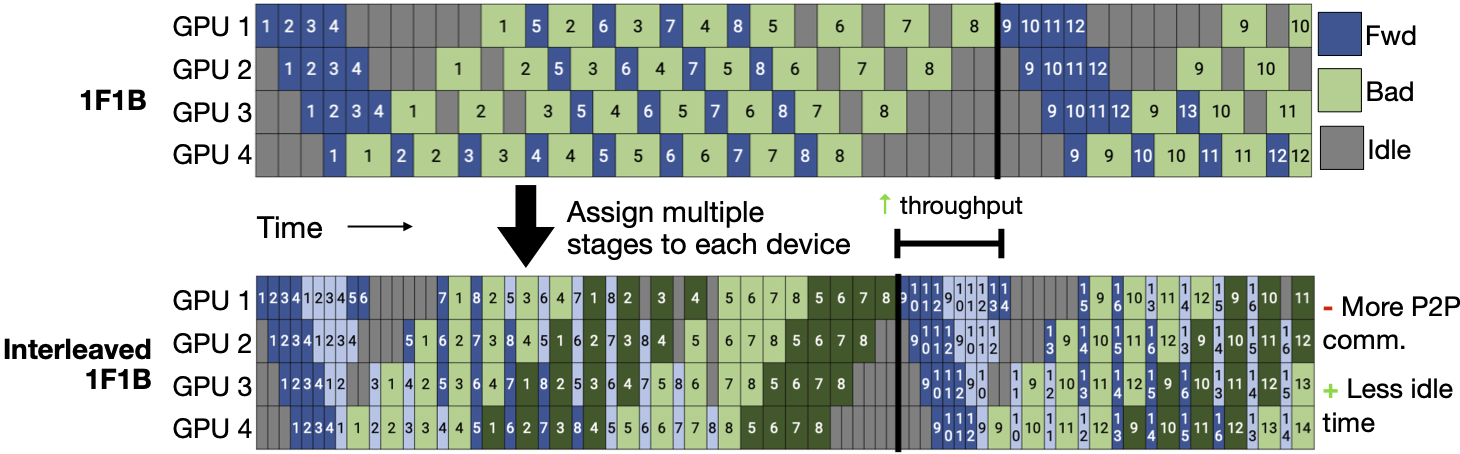
Due to the implementation complexity of coordinating any one schedule, existing training frameworks like Megatron-LM and DeepSpeed bake in only one or two different schedules and do not support schedule extensibility.
Core Innovations
Decouple Specification from Implementation
Piper’s key insight is to decouple the specification of the model and pipeline-parallel execution schedule from their distributed implementation.
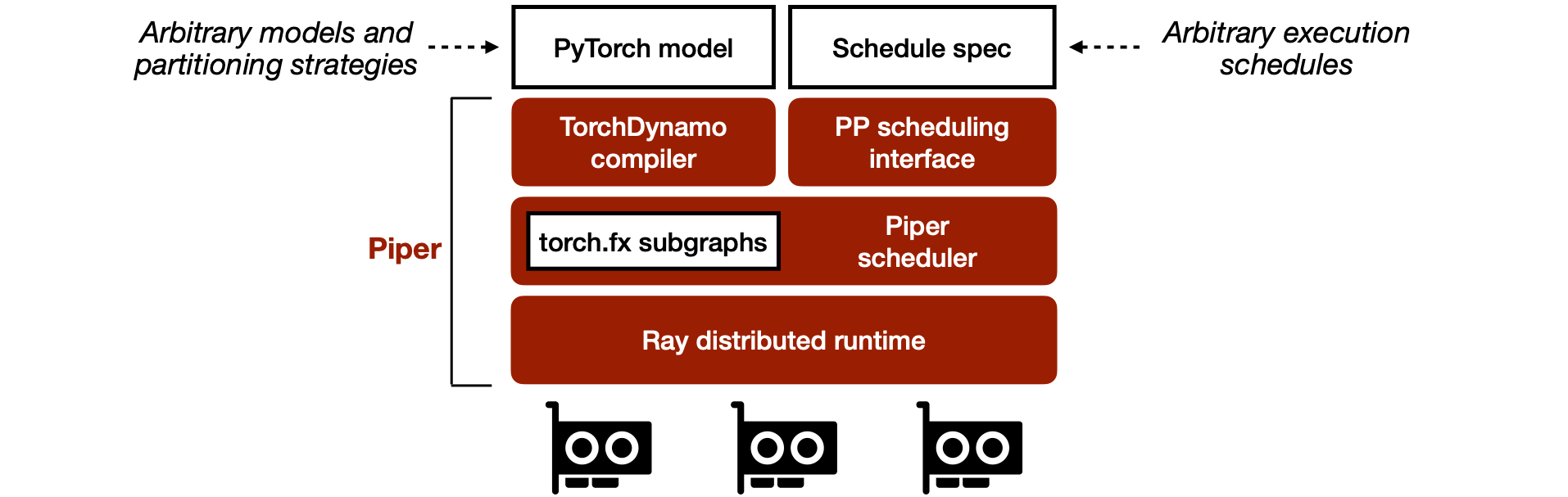
- Piper partitions arbitrary PyTorch models using the TorchDynamo JIT compiler to extract computation graphs, and leverages user annotations to partition the computation graphs into subgraphs for each pipeline stage.
- Piper proposes abstractions for specifying pipeline-parallel execution schedules at a high level. The distributed runtime takes care of coordinating and executing the schedules. Currently, Piper’s scheduling interface supports reordering and interleaving microbatches.
We aim to enrich the scheduling interface to support schedules that decompose operations within stages (e.g., ZeroBubble) and overlap communication and computation operations (e.g., DualPipe).
Flexible Coordination with a Single-Controller Distributed Runtime
Piper uses a single-controller distributed runtime to flexibly coordinate a high-level schedule specification. We use Ray as an RPC layer to manage distributed workers.
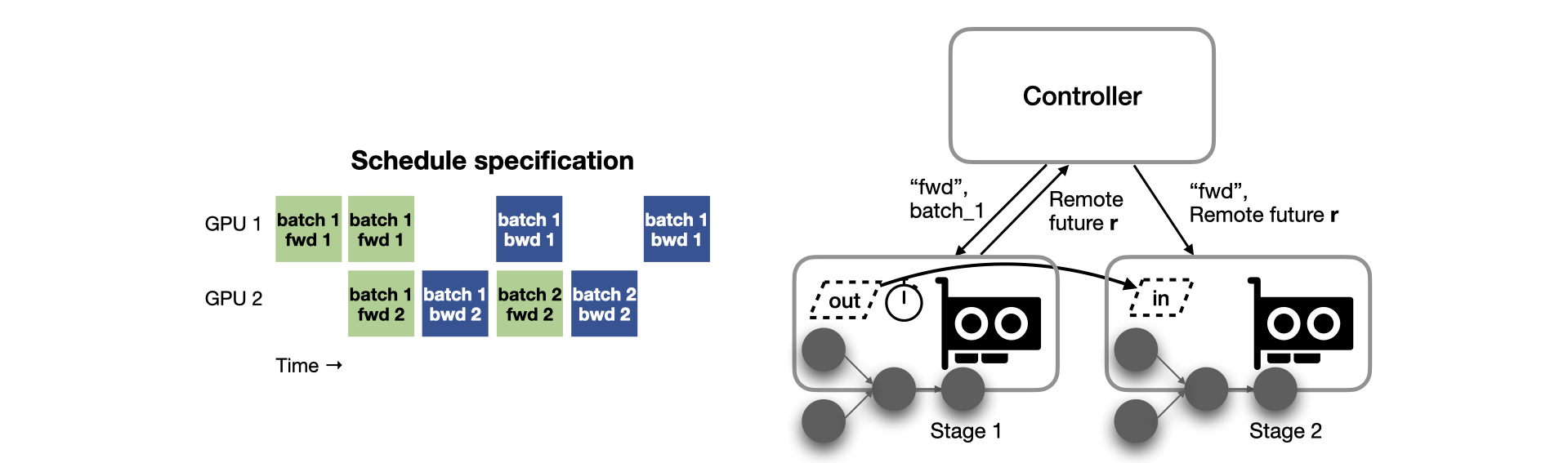
The controller distributes computation subgraphs, model parameters and optimizer states to workers, and dispatches forward and backward tasks for each batch based on the schedule specification. Piper uses futures for asynchronous execution. A future represents a value that will eventually be computed, which lets the controller run ahead of workers scheduling tasks to hide RPC overhead. Remote futures keep data on the workers to avoid materializing data on the controller. When an output tensor is ready, it transfers directly between workers using a pluggable communication backend.
Performance Benchmarks
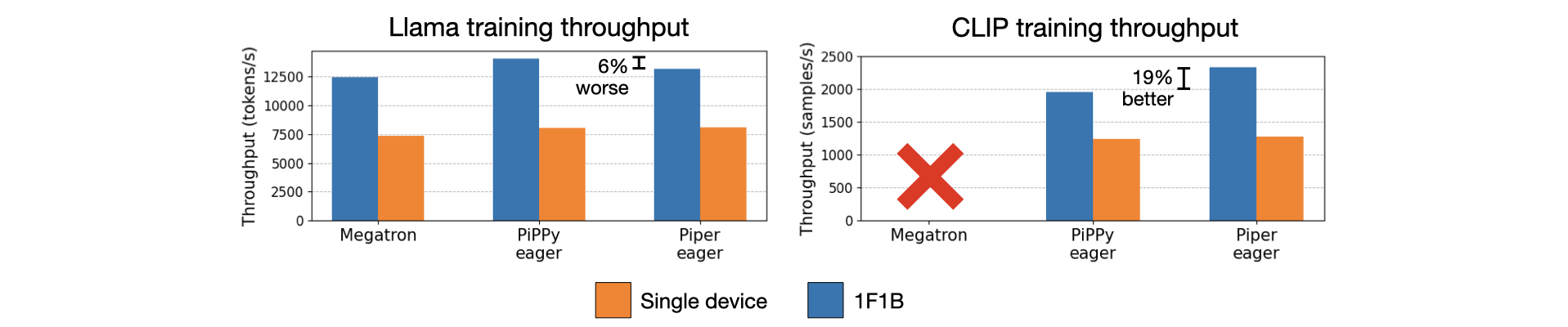
Piper achieves comparable preliminary performance with state-of-the-art distributed training frameworks. We compare training throughput pipelining a Llama model with Megatron-LM, PyTorch’s pipeline parallelism package (PiPPy), and Piper. Piper has 6% lower throughput than PiPPy due to RPC overhead. We plan to eliminate RPC overhead by exploring compiled Ray programs, which schedule communication operations ahead of time.
We also evaluate training throughput on the CLIP multi-modal model. Megatron only supports transformer models, so we can’t evaluate it on CLIP. CLIP has image and text encoder submodules that we partition into independent pipeline stages. PiPPy only supports sequential pipeline stages, forcing the image and text encoder stages to run sequentially. Piper executes these stages concurrently and achieves 19% higher training throughput.
Key Takeaways and Future Work
Decoupling enables extensibility. By decoupling the specification of pipeline-parallel execution schedules from their implementation, Piper enables further improvements to the usability and flexibility of the scheduling language and distributed runtime independently of each other.
Next: Interoperability with other parallelism strategies. Combining parallelism strategies (e.g. PPxFSDP and PPxEP) complicates communication patterns and requires carefully coordinating communication operations across strategies to avoid interference. We plan to support and explore these kinds of schedules in Piper.