NanoFlow: Towards Optimal Large Language Model Serving Throughput
Kan Zhu, Yufei Gao, Yilong Zhao, Liangyu Zhao, Gefei Zuo, Yile Gu, Dedong Xie, Tian Tang, Qinyu Xu, Zihao Ye, Keisuke Kamahori, Chien-Yu Lin, Ziren Wang, Stephanie Wang, Arvind Krishnamurthy, Baris Kasikci — Symposium on Operating Systems Design and Implementation (OSDI) (2025)
LLM Serving
Keywords: Large Language Models Inference Serving Intra-Device Parallelism Throughput Optimization Hardware Efficiency
Overview
NanoFlow is a high-performance serving framework designed to maximize hardware resource utilization for Large Language Model inference. Unlike traditional approaches that assume LLM serving is memory-bound, NanoFlow demonstrates that end-to-end serving is actually compute-bound, opening new opportunities for performance optimization through intelligent parallelism.
Core Innovations
🚀 Intra-Device Parallelism
NanoFlow’s key innovation is intra-device parallelism that overlaps compute-, memory-, and network-bound operations within a single device:
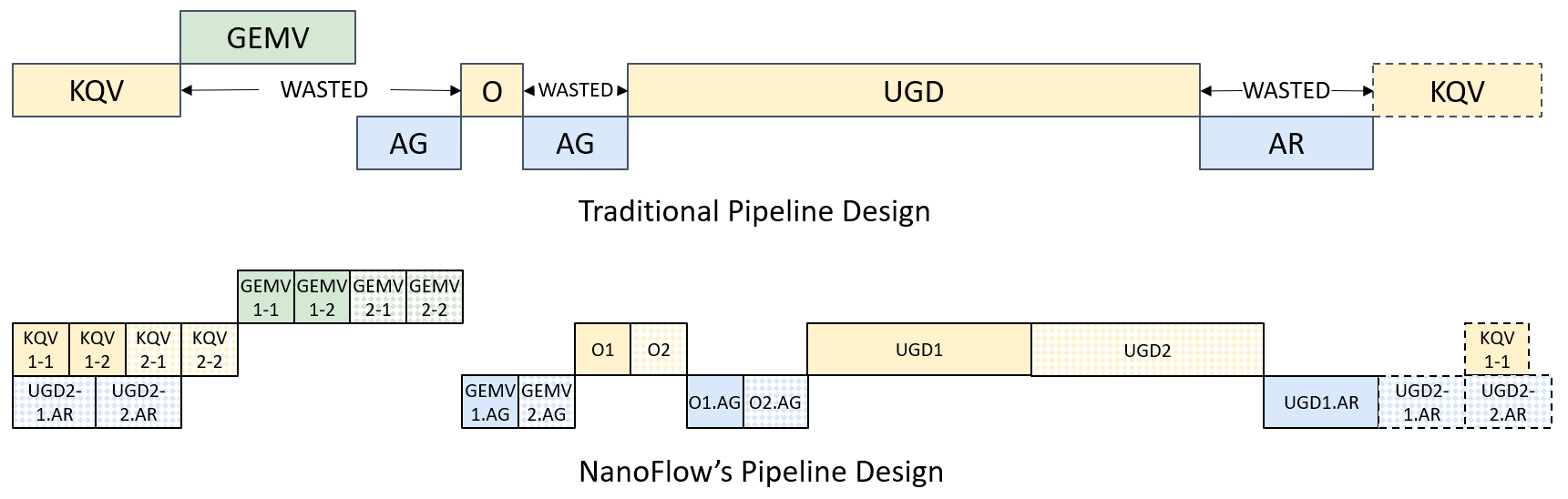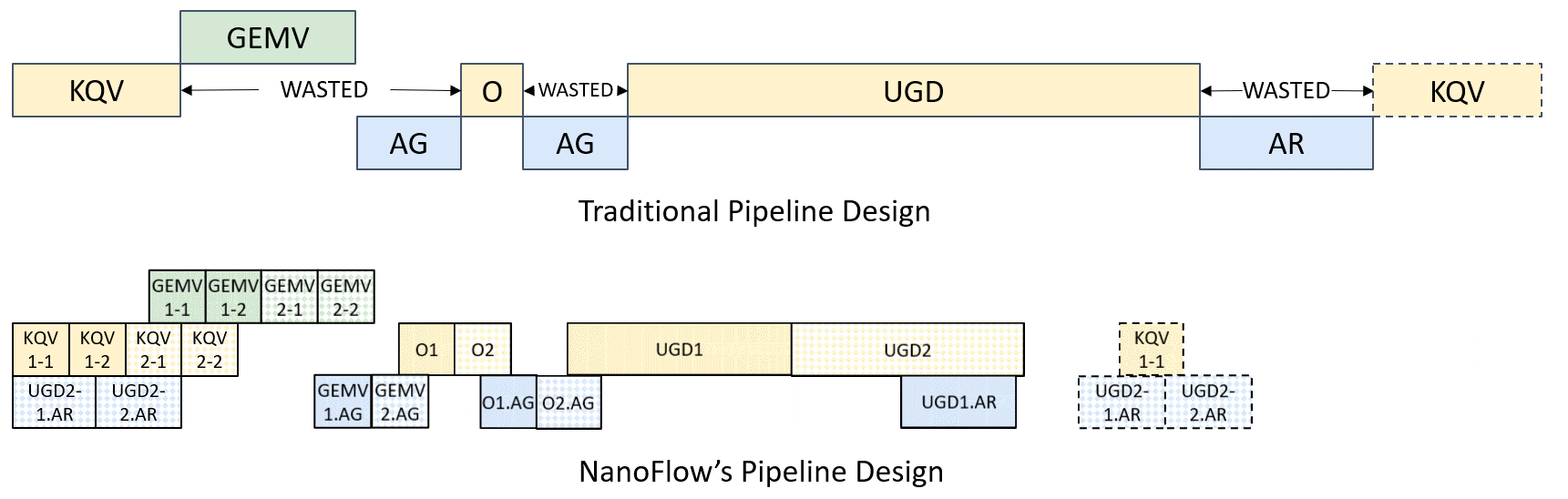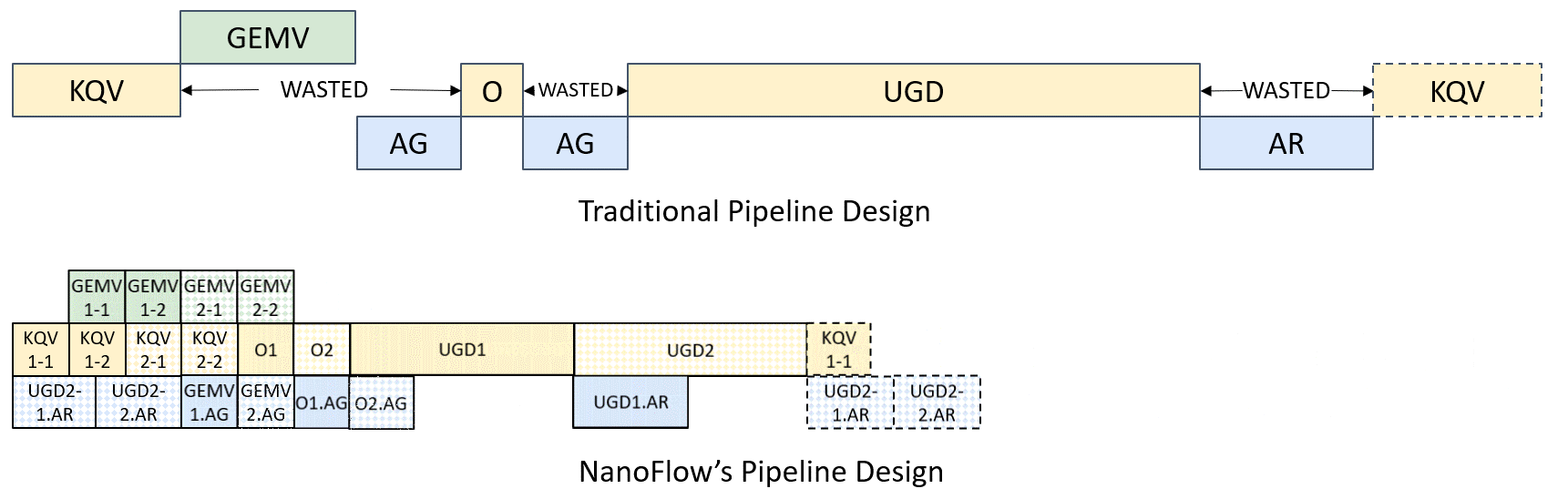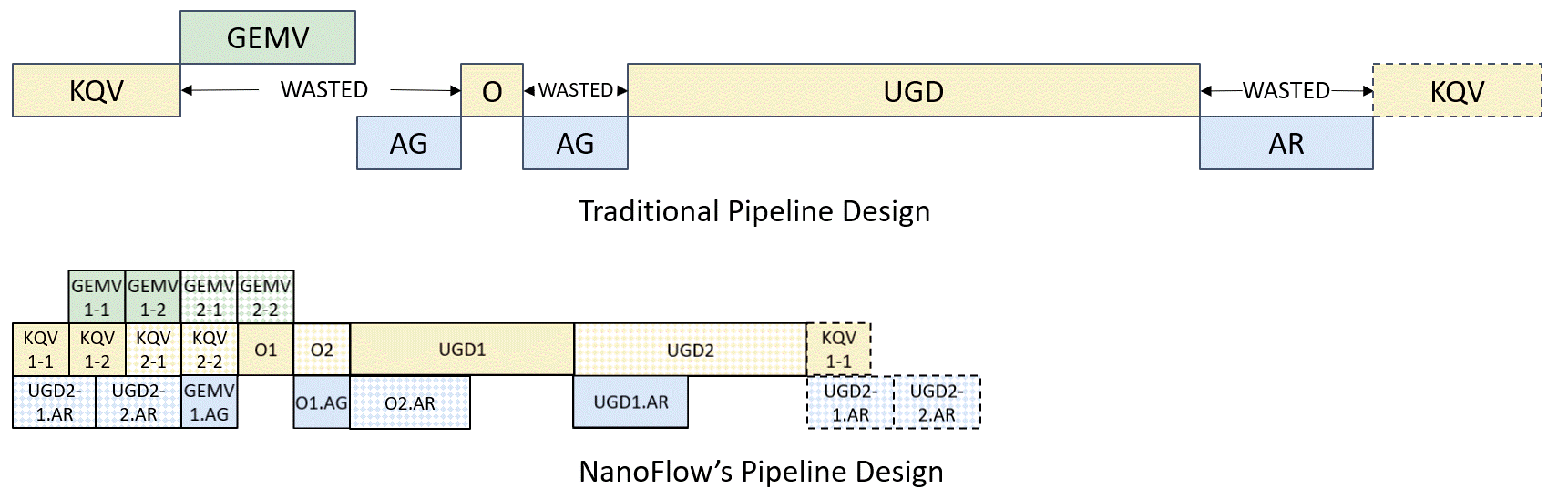
- Nano-batching: Breaks down batches into smaller units for fine-grained scheduling
- Execution unit scheduling: Dynamically schedules operations across different hardware components
- Pipeline overlapping: Simultaneously executes different operation types to maximize hardware utilization
⚡ Asynchronous CPU Scheduling
Efficient CPU-side management that complements GPU execution:
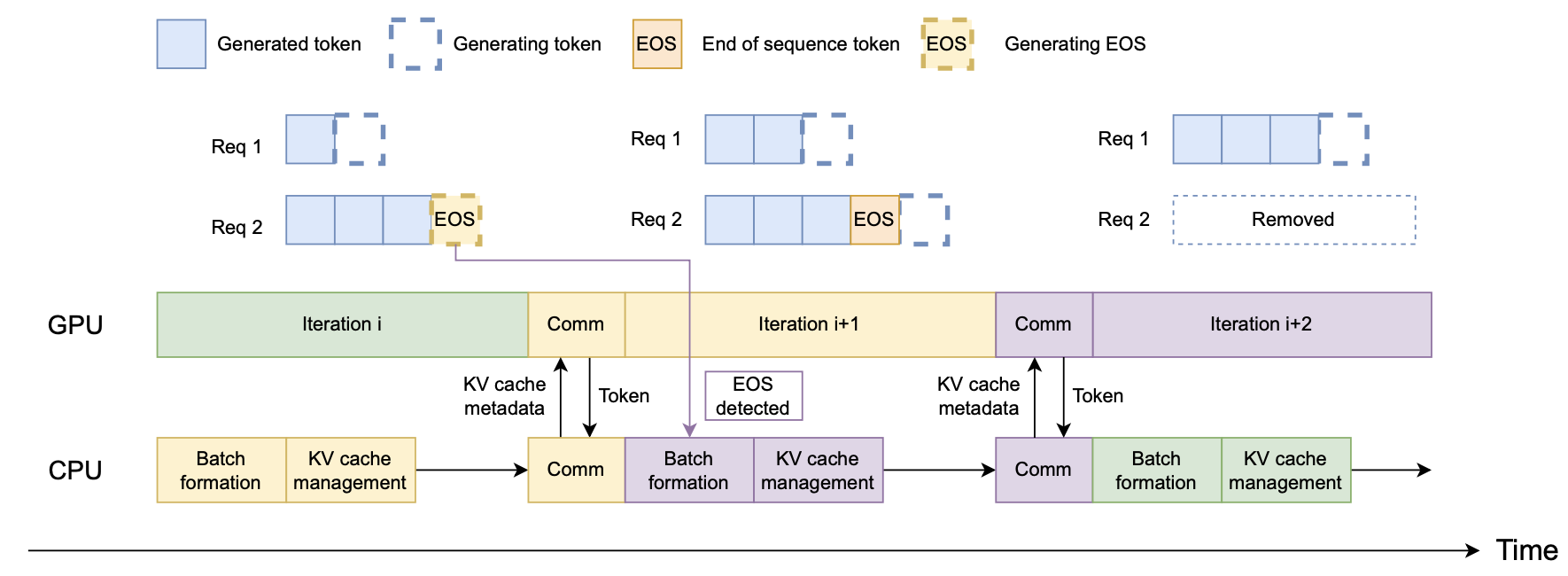
- Asynchronous batch formation: Prepares next batches while GPU is processing
- Intelligent KV-cache management: Eagerly offloads finished request caches to SSD
- Optimized control flow: Minimizes CPU-GPU synchronization overhead
🔧 Automatic Optimization
- Self-tuning system that adapts to different model architectures
- Automatically determines optimal nano-batch sizes
- No manual parameter tuning required for deployment
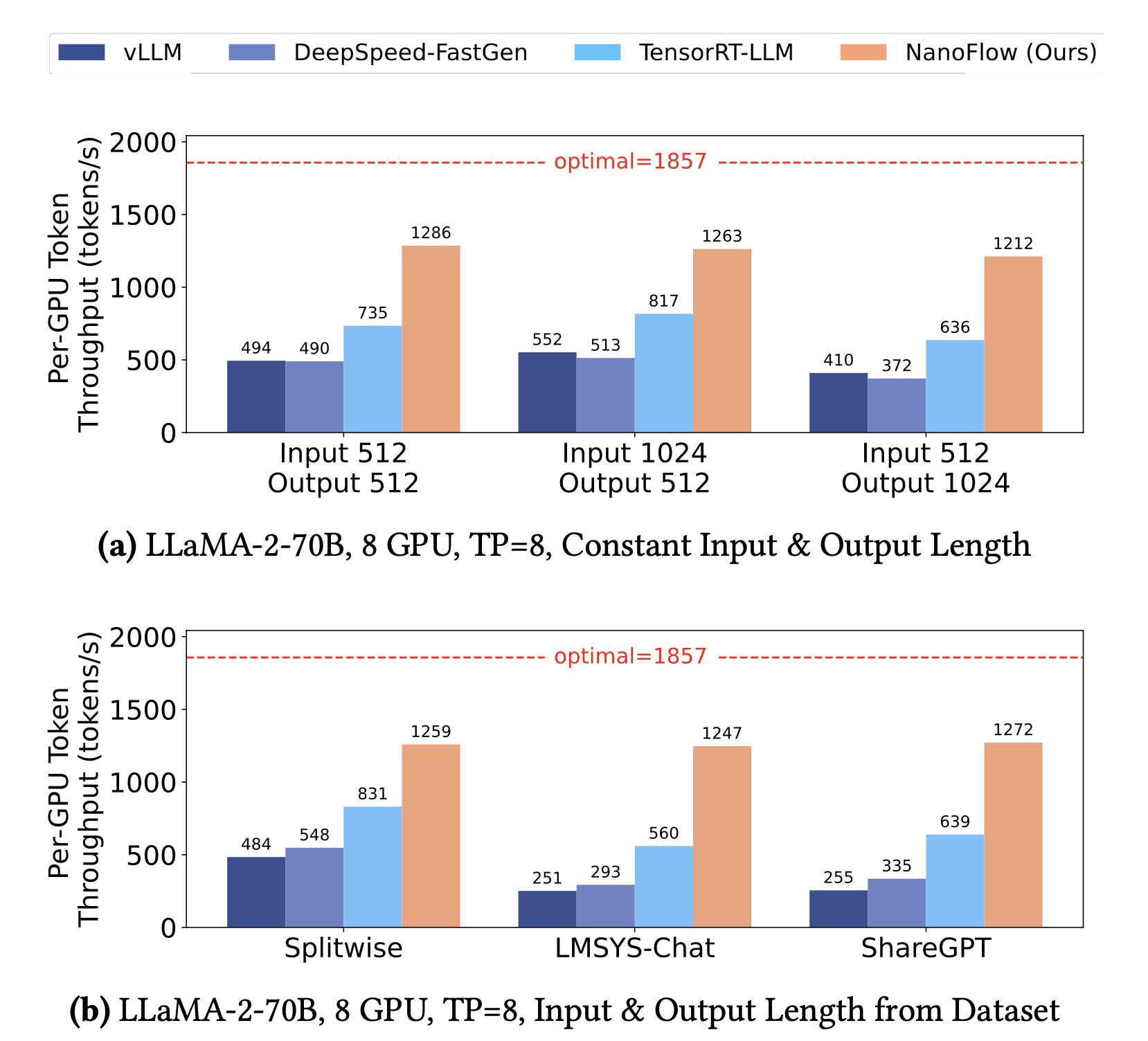
Performance Benchmarks
NanoFlow consistently outperforms state-of-the-art LLM serving systems:
| System | Relative Throughput |
|---|---|
| NanoFlow | 1.91x |
| TensorRT-LLM | 1.0x (baseline) |
| vLLM | 0.85x |
| Deepspeed-FastGen | 0.72x |
Tested Models
- ✅ LLaMA-2 70B
- ✅ LLaMA-3 70B & 8B
- ✅ LLaMA-3.1 70B & 8B
- ✅ Mixtral 8x7B
- ✅ Qwen2 72B
Key Results
- 1.91x throughput improvement over TensorRT-LLM
- Achieves 68.5% of theoretical optimal throughput
- Consistent gains across different model sizes and architectures
- Scales efficiently from 8B to 70B+ parameter models
System Architecture
NanoFlow’s architecture is built on three key layers:
- Device-Level Pipeline: Breaks traditional sequential execution into parallel stages
- Execution Unit Scheduler: Coordinates compute, memory, and network operations
- Asynchronous Control Plane: Manages batch formation and resource allocation independently
This multi-layered approach enables NanoFlow to:
- Eliminate pipeline bubbles and idle time
- Maximize GPU compute utilization
- Minimize memory bandwidth bottlenecks
- Reduce end-to-end latency while improving throughput
Key Takeaways
LLM serving workloads mix multiple types of resources - compute, memory, network, and storage. Traditional systems execute these operations sequentially, leaving resources idle while waiting for one type of operation to complete.
Concurrent kernel execution across heterogeneous resources unlocks hidden parallelism. By running multiple operations simultaneously (e.g., GPU compute while memory transfers data, CPU preparing batches while GPU executes), NanoFlow keeps all resources busy at the same time rather than waiting in sequence - this is the key to achieving the 1.91x performance boost.