LiteASR: Efficient Automatic Speech Recognition with Low-Rank Approximation
Keisuke Kamahori, Jungo Kasai, Noriyuki Kojima, Baris Kasikci — Conference on Empirical Methods in Natural Language Processing (EMNLP) (2025)
Efficient ML Speech
Keywords: Automatic Speech Recognition Model Compression Low-Rank Approximation Whisper Efficiency
Overview
LiteASR is a novel compression scheme designed to address the computational bottlenecks in modern Automatic Speech Recognition (ASR) encoders. While recent advances like Distill-Whisper have successfully compressed decoders, the encoder remains a massive, compute-bound component.
LiteASR demonstrates that intermediate activations in ASR encoders exhibit strong low-rank properties. By exploiting this structure, LiteASR approximates linear layers and self-attention mechanisms, significantly reducing model size and latency without retraining the model from scratch.
Core Innovations
📉 Activation-Aware Low-Rank Compression
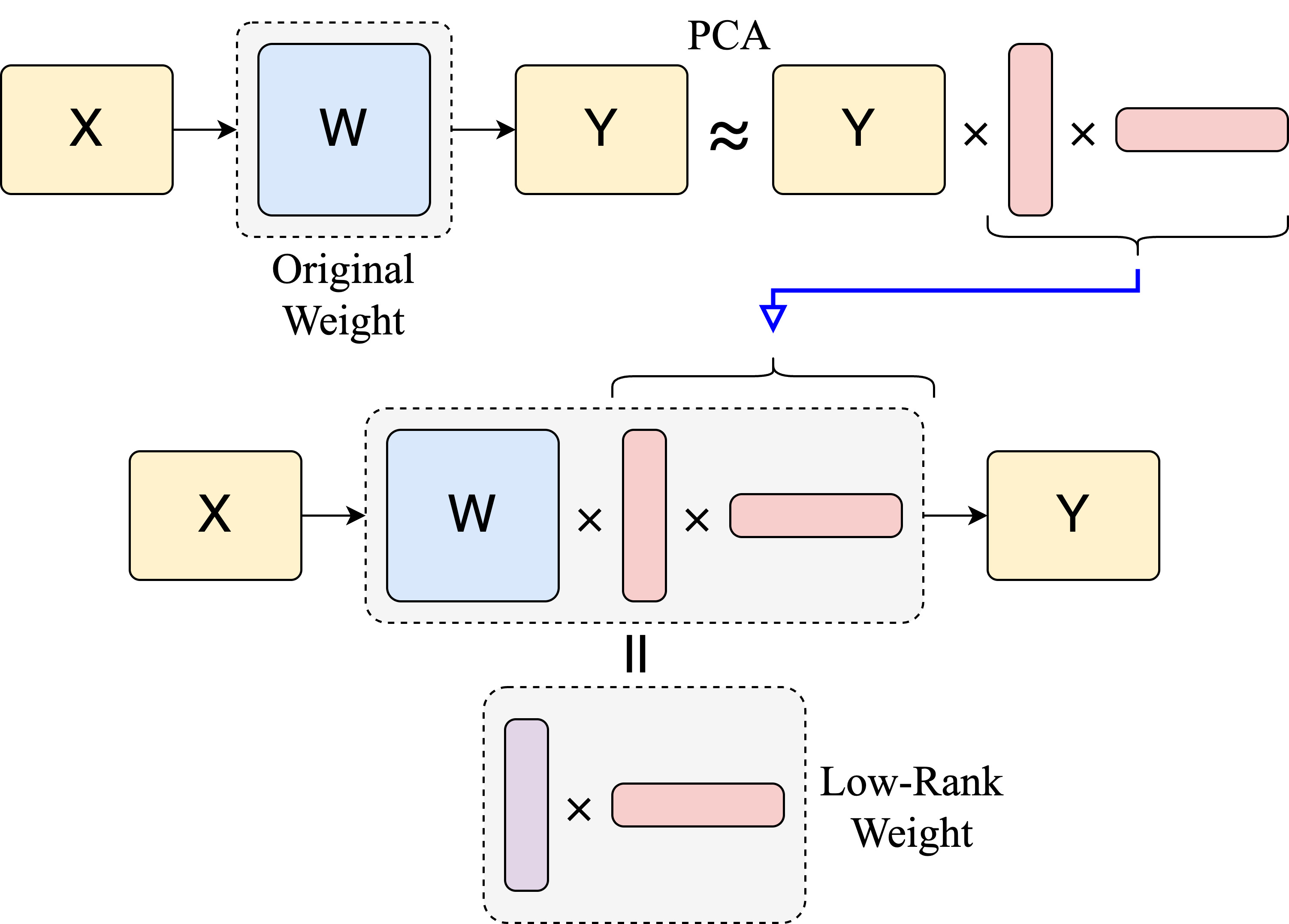
Unlike traditional pruning or quantization that focuses solely on model weights, LiteASR analyzes the activations generated during inference.
- Calibration Phase: Uses a small dataset to record input/output activations for each layer.
- PCA Decomposition: Applies Principal Component Analysis (PCA) to identify the dominant components in the activation space.
- Matrix Factorization: Decomposes large weight matrices into chains of smaller, low-rank matrices that approximate the original linear transformation with fewer FLOPs.
⚡ Optimized Self-Attention
LiteASR goes beyond simple linear layers by optimizing the self-attention mechanism itself:
- Dimensionality Reduction: Projects queries and keys into a lower-dimensional space before attention calculation.
- Rank-Adaptive: Automatically determines the optimal rank ($k$) for each layer based on a preserved variance threshold ($\theta$), ensuring critical information is retained.
Performance Benchmarks
LiteASR consistently outperforms stock Whisper models, establishing a new Pareto frontier for ASR efficiency.
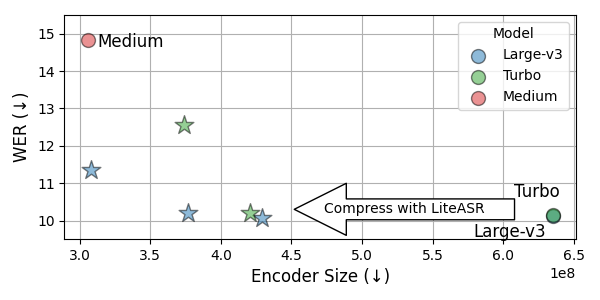
Key Results
- ~1.4x Speedup: Achieves significant inference acceleration on both GPUs and edge devices (e.g., Apple M-series chips).
- Zero Accuracy Loss: The “Acc” configuration matches the original Whisper Large v3 WER (10.1) while reducing encoder parameters by 200M+.
- Better than Medium: The “Fast” configuration is the same size as Whisper Medium but achieves 3.5% lower WER (11.3 vs 14.8).
System Architecture
LiteASR’s architecture focuses on transforming the standard Transformer encoder blocks into efficient Low-Rank (LR) equivalents.
- Data Analysis: The system first runs a forward pass with calibration data to collect activation statistics.
- SVD & Rank Selection: It performs Singular Value Decomposition (SVD) on the centered activations to find the optimal rank $k$ that captures $\theta\%$ of the variance.
- Layer Replacement:
- MLP Layers: The two large linear layers in the Feed-Forward Network are replaced by low-rank factored matrices.
- Attention Layers: The $Q, K, V$ projections and the Output projection are compressed. The attention computation itself occurs in the reduced rank space.
This approach ensures that the compression is data-driven, adapting to the actual information flow within the network rather than arbitrary weight magnitudes.
Key Takeaways
Encoders are the new bottleneck. With the advent of distilled decoders (like Distill-Whisper), the heavy lifting has shifted to the encoder. LiteASR directly targets this bottleneck.
Activations tell the truth. Weight-based compression often misses redundant neurons that appear important but contribute little to actual signal variance. LiteASR’s activation-based analysis is more precise.
Drop-in Replacement. The resulting “Lite-Whisper” models are architecturally compatible with existing serving pipelines (like Hugging Face Transformers or Triton), requiring no complex hardware-specific kernels to see gains.