Fiddler: CPU-GPU Orchestration for Fast Inference of Mixture-of-Experts Models
Keisuke Kamahori, Tian Tang, Yile Gu, Kan Zhu, Baris Kasikci — International Conference on Learning Representations (ICLR) (2025)
LLM Serving
Keywords: Large Language Models Mixture-of-Experts Local Inference CPU-GPU Orchestration Inference Serving Latency Optimization
Overview
Fiddler is a specialized inference system designed to run large Mixture-of-Experts (MoE) models in resource-constrained environments where GPU memory is insufficient to hold the full model. Existing methods rely on offloading model weights to CPU memory and transferring them to the GPU on-demand, which is severely bottlenecked by the limited PCIe bandwidth. Fiddler challenges this paradigm by demonstrating that for single-batch, latency-critical inference, it is often faster to execute expert layers directly on the CPU rather than transferring their weights to the GPU.
Core Innovations
🎻 CPU-GPU Orchestration
The core innovation of Fiddler is its ability to dynamically orchestrate computation between the CPU and GPU based on resource availability and performance characteristics:
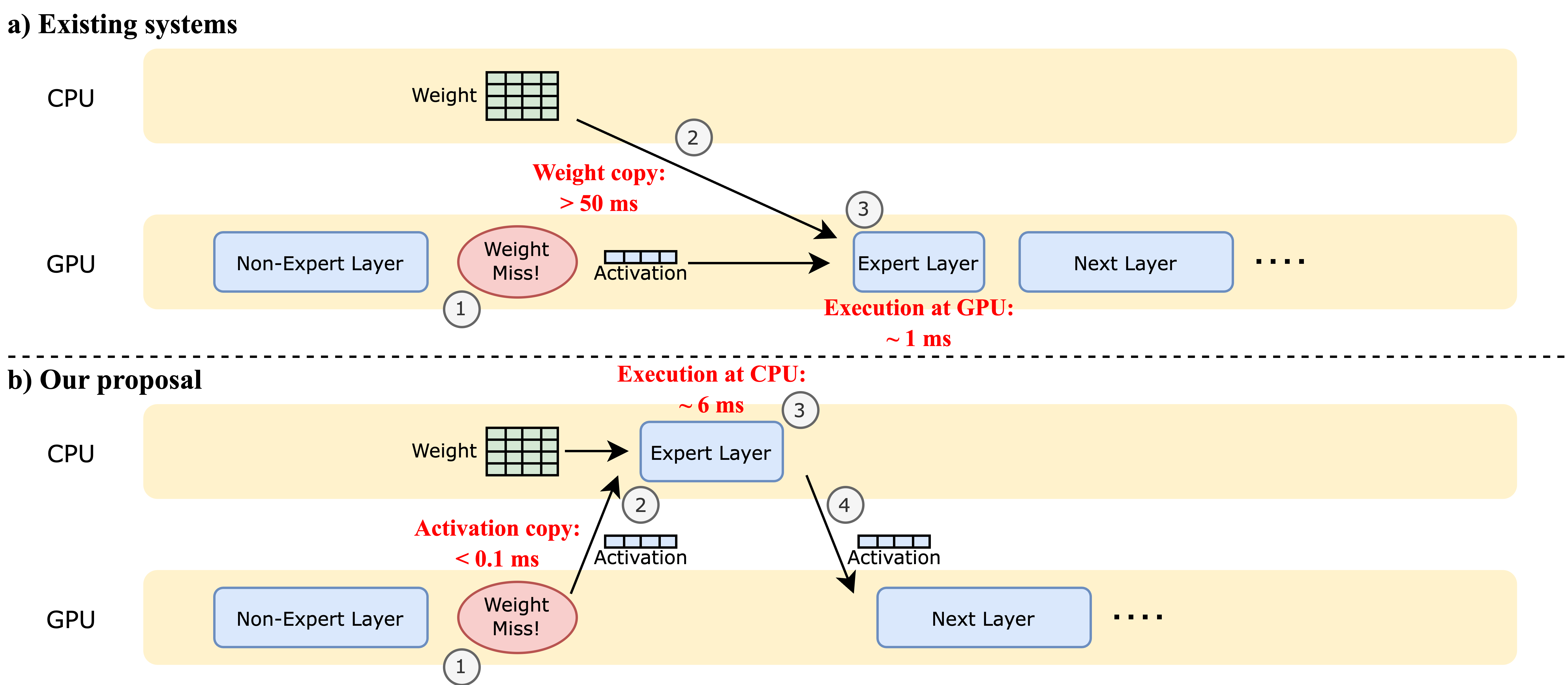
- Compute-Centric Offloading: Instead of moving heavy expert weights (GBs) to the GPU, Fiddler moves the much smaller activation data (MBs) to the CPU for computation.
- Latency-Aware Decision Making: The system analyzes the trade-off between data transfer latency and computation latency to determine the optimal execution path for each layer.
- Resource Synergy: Utilizes the often-idle CPU computational power to assist the GPU, effectively expanding the hardware capabilities for inference.
⚡ Minimized Data Movement
Fiddler fundamentally changes the data movement patterns in MoE inference:
- Weight Retention: Keeps large expert weights in CPU RAM, avoiding the high latency of moving them over PCIe.
- Activation Transfer: Transfers only the necessary activation tensors between GPU and CPU, which is significantly faster due to their small size (e.g., batch size $\times$ hidden dimension).
- Expert Locality: Non-expert layers (attention, dense) typically remain on the GPU, while sparse expert layers are routed to the CPU when GPU memory is full.
🔧 Optimized CPU Kernels
- Custom optimized kernels for expert layer computation on CPUs.
- Efficient thread management to maximize CPU core utilization during expert execution.
- Synergistic scheduling that overlaps GPU non-expert computation with CPU expert computation where possible.
Performance Benchmarks
Fiddler demonstrates substantial performance improvements over state-of-the-art offloading systems:
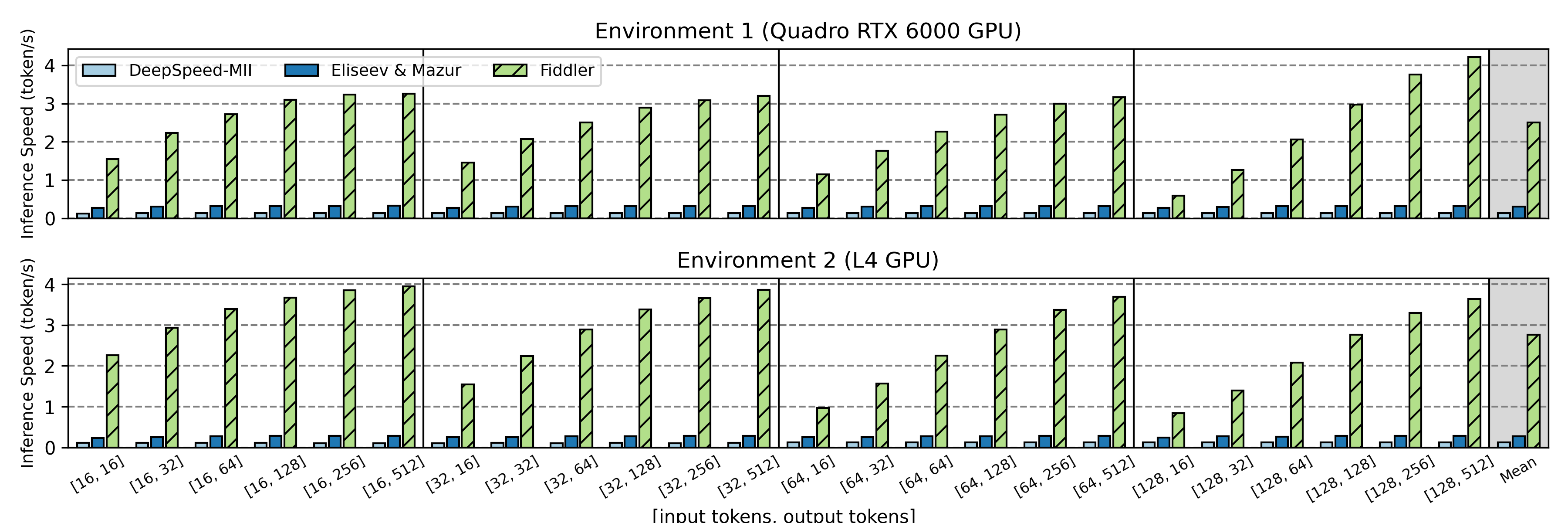
Key Results
- >3 tokens/second generation speed for unquantized Mixtral-8x7B on a single 24GB GPU.
- 8.2x - 10.1x speedup in single-batch inference latency compared to standard offloading methods.
- Enables running >90GB models on devices with limited GPU memory without severe performance penalties.
System Architecture
Fiddler’s architecture is designed to bridge the gap between memory capacity and compute capability:
- Model Partitioner: Splits the MoE model into GPU-resident components (attention layers, gate networks) and CPU-resident components (expert weights).
- Orchestration Engine: At runtime, the engine intercepts expert layer calls. It checks if the required experts are on the GPU. If not, it seamlessly transfers activations to the CPU.
- Hybrid Execution Pipeline:
- GPU: Handles attention mechanisms and hot experts (if caching is used).
- CPU: Handles the “long tail” of diverse experts that cannot fit in GPU memory.
- PCIe Bus: Used strictly for lightweight activation transfer rather than heavy weight swapping.
This design eliminates the “PCIe wall” that typically freezes inference while waiting for weights to load, ensuring a smooth and continuous token generation process.
Key Takeaways
Data movement is the primary bottleneck for local LLM inference, especially for sparse models like MoE where only a fraction of parameters are used per token.
Compute is often cheaper than communication. Fiddler proves that it is more efficient to perform calculations on a slower processor (CPU) where the data resides, rather than moving massive amounts of data to a faster processor (GPU). This “shipping compute to data” approach unlocks the ability to serve massive models on consumer-grade or single-GPU hardware with acceptable interactive performance.