Atom: Low-bit Quantization for Efficient and Accurate LLM Serving
Yilong Zhao, Chien-Yu Lin, Kan Zhu, Zihao Ye, Lequn Chen, Size Zheng, Luis Ceze, Arvind Krishnamurthy, Tianqi Chen, Baris Kasikci — Annual Conference on Machine Learning and Systems (MLSys) (2024)
LLM Serving
Keywords: Large Language Models Quantization Low-bit Inference Model Compression GPU Optimization
Overview
Atom is an accurate low-bit weight-activation quantization algorithm designed to dramatically improve LLM serving efficiency. While modern GPUs have powerful 4-bit integer operators, existing quantization methods fail to fully exploit these capabilities. Atom bridges this gap by introducing a novel quantization approach that maximizes hardware utilization while preserving model accuracy.
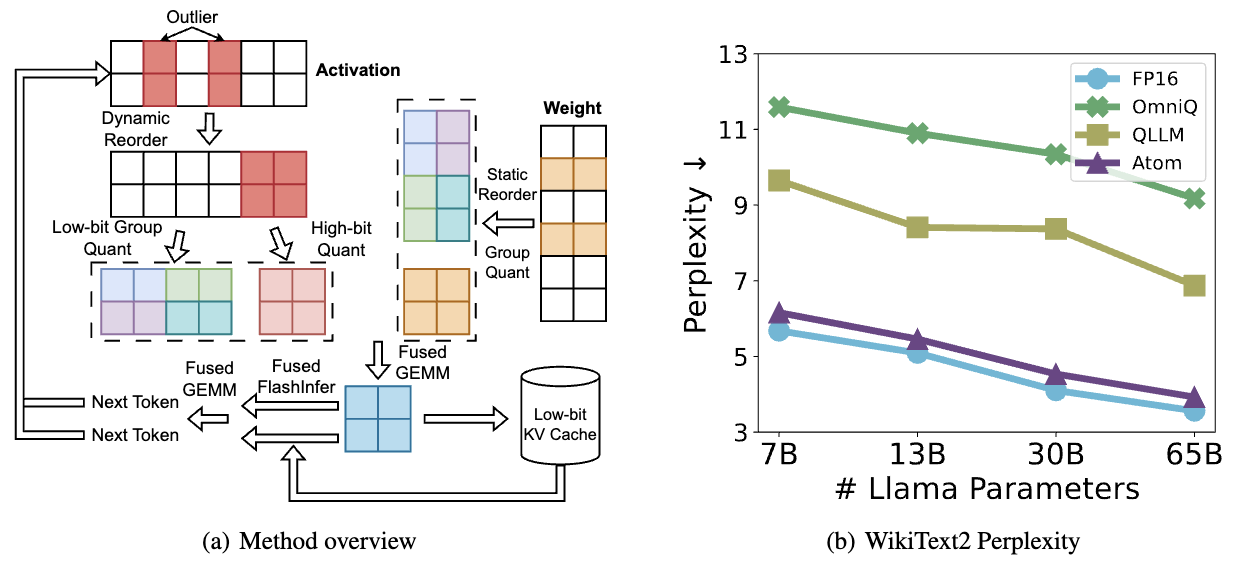
Core Innovations
🎯 Mixed-Precision Quantization
Atom intelligently applies different precision levels across model components:
- Critical layers: Higher precision for accuracy-sensitive operations
- Quantizable layers: Aggressive 4-bit quantization for throughput gains
- Adaptive strategy: Automatically determines optimal precision per layer
- Minimal accuracy impact: Maintains model performance within acceptable bounds
⚡ Fine-Grained Group Quantization
Instead of quantizing entire tensors uniformly:
- Group-level quantization: Divides tensors into smaller groups with individual scales
- Better precision preservation: Captures fine-grained value distributions
- Reduced quantization error: Each group optimizes its own quantization parameters
- Hardware-friendly design: Group sizes aligned with GPU execution patterns
🔄 Dynamic Activation Quantization
Handles the challenge of varying activation ranges:
- Runtime calibration: Computes quantization parameters during inference
- Per-token adaptation: Adjusts to input-specific activation distributions
- Outlier handling: Special treatment for extreme activation values
- Efficient implementation: Minimal overhead for dynamic operations
💾 KV-Cache Quantization
Extends quantization benefits to attention mechanisms:
- Memory footprint reduction: Compresses key-value caches significantly
- Bandwidth optimization: Reduces data transfer between memory and compute
- Attention quality preservation: Maintains attention score accuracy
- Scalable to long contexts: Enables longer sequence handling
🚀 Efficient CUDA Kernel Design
Custom kernel implementations optimized for quantized operations:
- INT4 and FP4 support: Native 4-bit integer and floating-point operations
- Fused operations: Combines dequantization with computation kernels
- Memory coalescing: Optimizes memory access patterns
- Hardware utilization: Maximizes GPU tensor core usage
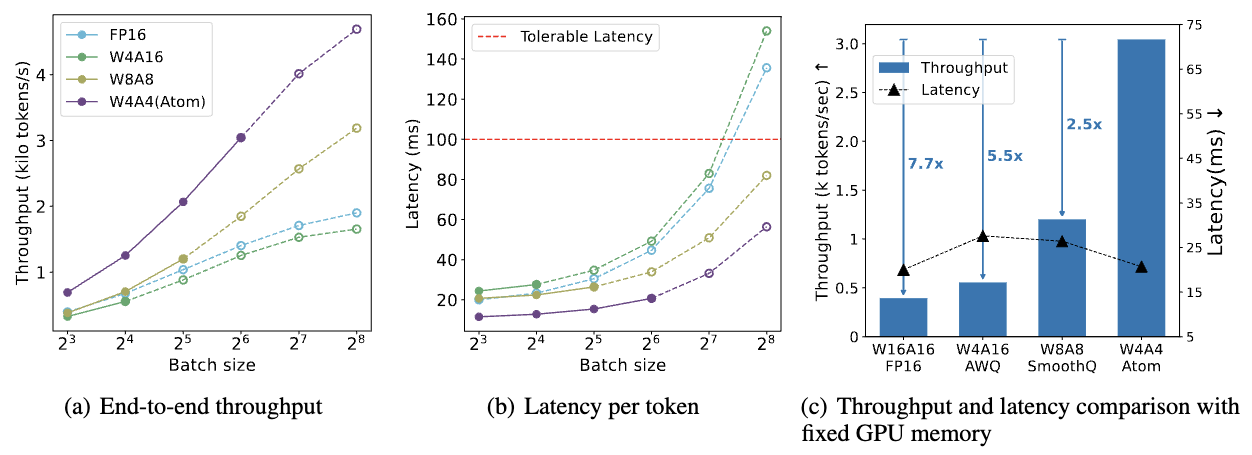
Performance Benchmarks

Atom achieves substantial throughput improvements across different model families:
| Baseline | Throughput Improvement |
|---|---|
| FP16 | Up to 7.73x |
| INT8 | Up to 2.53x |
Tested Models
- ✅ LLaMA (7B, 13B, 30B, 65B)
- ✅ LLaMA-2 (7B, 13B, 70B)
- ✅ Mixtral 8x7B
Accuracy Preservation
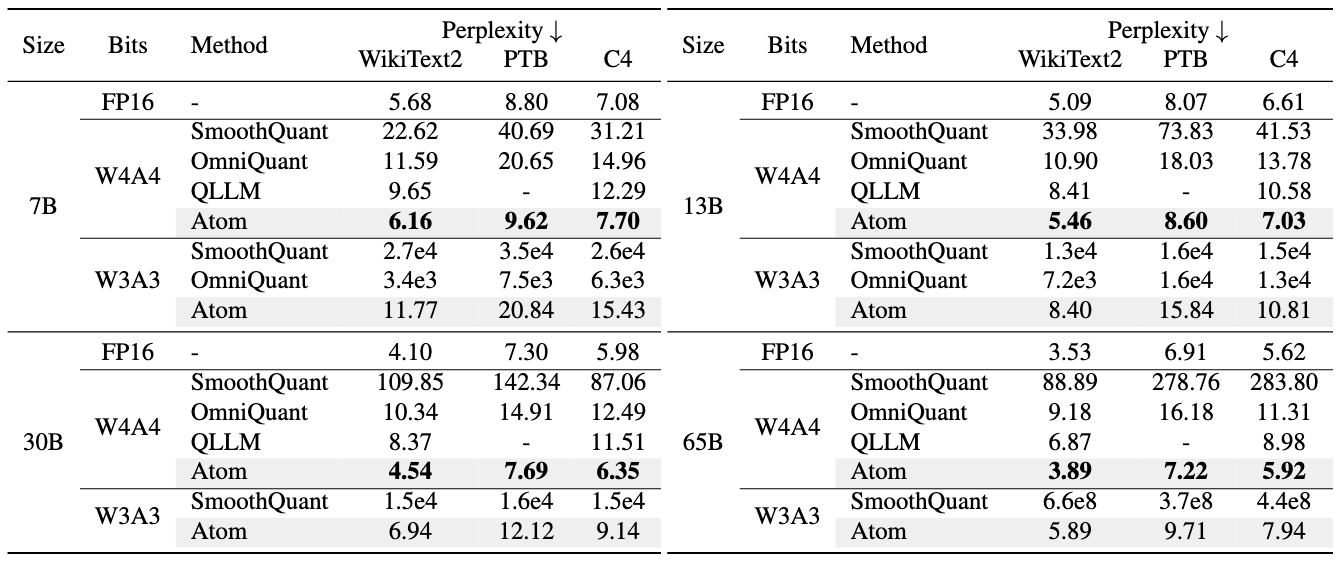
- Perplexity: Negligible increase compared to full precision
- Zero-shot accuracy: Maintains performance on downstream tasks
- Consistent quality: Works across different model sizes and architectures
Technical Approach
Atom’s quantization pipeline consists of:
- Calibration Phase: Analyzes model weight and activation distributions
- Precision Selection: Determines optimal bit-width for each layer
- Quantization Parameter Computation: Calculates scales and zero-points
- Kernel Optimization: Generates efficient CUDA code for quantized operations
- Runtime Execution: Performs inference with dynamic activation quantization
This multi-stage approach ensures that quantization is both aggressive (for performance) and careful (for accuracy).
Key Takeaways
4-bit quantization requires group quantization and mixed-precision for accuracy. Naive 4-bit quantization causes severe accuracy degradation. Atom demonstrates that combining fine-grained group quantization (which captures local value distributions) with mixed-precision strategies (applying different bit-widths to different layers) is essential to maintain model quality while achieving substantial performance gains.
Modern hardware now has built-in support for FP4 group quantization. Next-generation GPUs like NVIDIA’s B200 include native FP4 group quantization capabilities in their tensor cores, making widespread adoption of FP4 quantization feasible. This hardware-software co-design means that techniques like Atom can achieve even better performance on newer hardware, paving the way for efficient deployment of increasingly large models.